概要
WalkMeメニュー・エンタープライズ検索は、包括的で統一された検索体験を通じて、アプリケーションと資源を検索することができます。 WalkMeコンテンツと第三者のアプリの両方で情報を検索できる堅牢な検索エンジンとして機能し、コンソールの統合ページから追加されました。
エンタープライズ検索では、次の処理が実行されます。
- 迅速かつ効率的な知識発見を提供することで、複数の異なるデータソースから検索する必要性をなくする
- AIを活用しパーソナライズされた検索結果を生成し、ユーザーがアプリの種類やファイルの種類ごとにフィルタリングできる
- ビジネスのセキュリティとエンドユーザーのプライバシーを保護し、インデックス作成をゼロにしてアクセス権限を尊重する
詳細
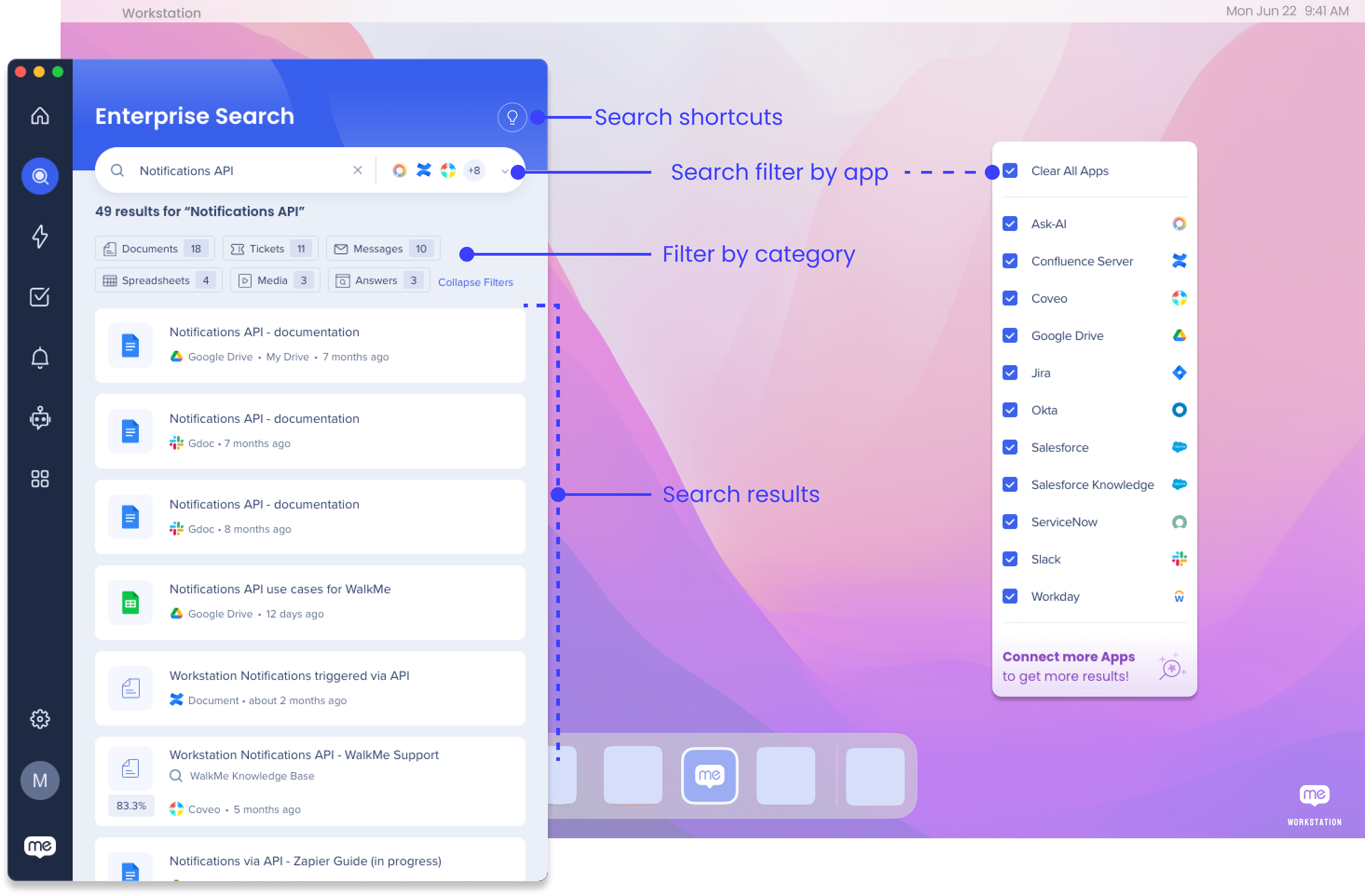
アプリ別にフィルタリング
統合されたすべてのアプリを検索したり、特定のアプリに対して検索をフィルタリングすることができます。
- 検索バーのドロップダウンをクリックする
- 検索をフィルタリングするアプリを選択する
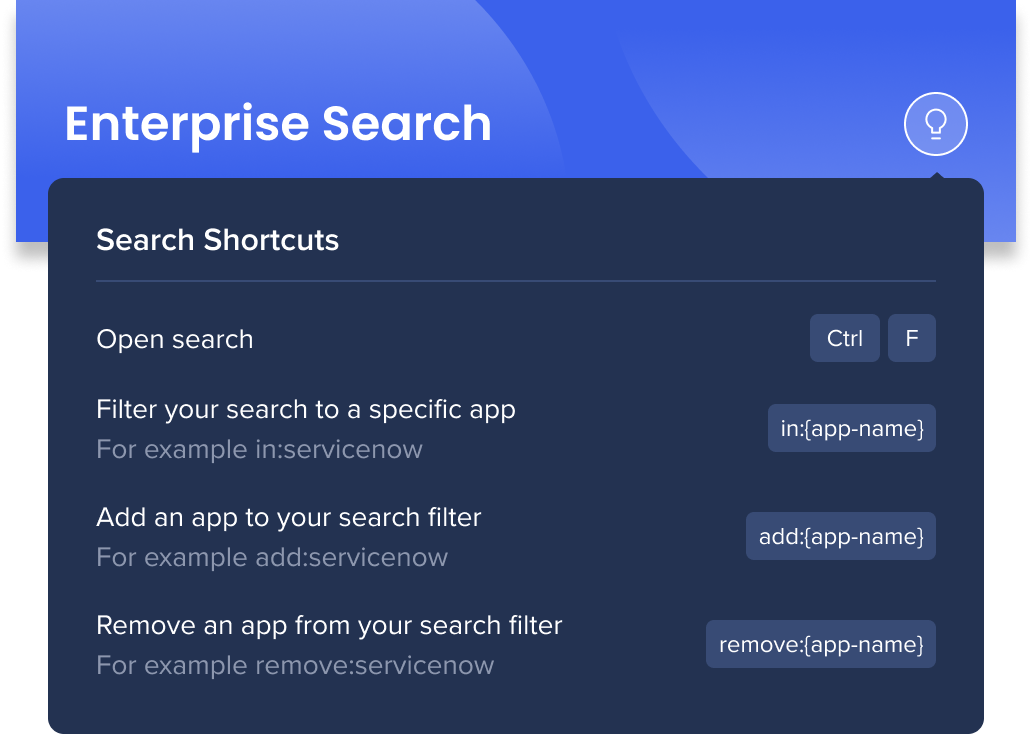
検索ショートカット
また、検索フィルターを変更せずにアプリを調整するために使用できるクイックキーボードショートカットもあります。
- 検索を開く:Ctrl/Cmd+Fを押す
- 検索を特定のアプリにフィルタリング:「in:{app name}」と入力する
- たとえば、フィルターですべてのアプリを選択し、「in:servicenow」と入力すると、ServiceNowからの結果だけが表示される
- ショートカットを削除してフィルターに戻る
- 検索フィルターにアプリを追加する:add:{app name}と入力する
- たとえば、検索をいくつかのアプリにフィルタリングし、フィルターを調整せずにServiceNowを追加する場合は、「add:servicenow」と入力する
- ショートカットを削除してフィルターに戻る
- 検索フィルターからアプリを削除する:「remove:{app name}」と入力する
- たとえば、ServiceNowの結果を表示しない場合は、 「remove:servicenow」と入力する
- ショートカットを削除してフィルターに戻る
カテゴリ別にフィルタリング
検索結果がロードされると、追加のカテゴリフィルターが表示されます。 これにより、コンテンツタイプへの検索をさらに指定できます。
例えば、文書を探していることがわかっていても、どのアプリのものなのか覚えていない場合などに便利です。 「ドキュメント」ボタンをクリックするだけで、検索フィルター内のすべてのアプリにまたがるドキュメントだけが検索されます。
カテゴリフィルターには、検索結果に表示されたコンテンツタイプだけが表示されます。 したがって、結果のいずれも文書でない場合、文書カテゴリは選択されません。

可能なすべてのカテゴリのリストは、ここをクリックしてください...
- ドキュメント
- チケット
- メッセージ
- スプレッドシート
- メディア
- 回答
- ActionBot
- Resource
- コード
- 条件
- 商談
- アカウント
- イベント
- レポート
- Apps(アプリ)
- プレゼンテーション
- リード
- ウェブサイト
検索結果
検索結果には、コンテンツ名とどのアプリのものが表示されます。 結果をクリックすると、ホームページの「最近見たウィジェット」に表示されるので、すぐにそれに戻ることができます。
任意の言語で検索します
エンタープライズ検索は、すべての言語をサポートしています。 つまり、希望する言語で検索できるため、必要な情報を見つけることが容易で迅速になります。
自動修正
ユーザーは、正確なスペルまたは正確な一致について心配する必要がなくなりました。 検索機能は、検索クエリにマイナーなエラーまたはスペルミスがある場合でも、意図をインテリジェントに理解し、最も関連した結果を提供します。
使用方法:
- オープンソースライブラリ(非AI):オープンソースライブラリは、検索クエリで一般的な文法と語彙エラーを修正します。 オープンソースライブラリの自動修正は、英語のみをサポートしています。
- OpenAI統合:OpenAIとの統合は、AIベースのアルゴリズムを使用して、検索クエリ修正を次のレベルに引き上げます。 OpenAI自動補正は、すべての言語をサポートします。
検索結果のソート
結果ソートフロー
エンタープライズ検索では、関連性に応じて結果をソートするソートサービスが使用されます。 ソートサービスがソートを実行する方法:
-
ユーザーがデスクトップ/モバイルのメニューアプリで用語を検索します
-
検索サービスは、接続されている各アプリのサービスの用語と呼び出しをリアルタイムで取得する
-
接続されているアプリの今期のサービス検索、 それぞれが独自のAPIコールと実装を持つ
-
検索サービスは、接続されているすべてのアプリからすべての検索結果を取得する
-
検索サービスが結果とともにソートサービスを呼び出す
-
ソートサービスは結果をソート/順序付けし、ソート/順序付けした結果を検索サービスに返送する
-
検索サービスは、結果をデスクトップ/モバイルのメニューアプリに返します
ソートの採点方法
ソーターサービスは、基本的なレベンシュテイン距離に加えて、ステューイング、ファジーネス、NLPなど9種類のスコアリング方法を使用しています。 各結果は、優先順位を設定するために0~1の範囲で9つのスコア(メソッドごとに1つ)を取得します。
-
LevenshteinFast:2つの文字列間のLevenshtein距離を計算するために使用される計算アルゴリズムで、一方の文字列を他方の文字列に変換するために必要な1文字の編集(挿入、削除、置換)の最小数の尺度である
-
JaroWinkler:2つの文字列間の類似性を比較するために使用される文字列類似性尺度
-
IdenticalTokens:同じ単語(トークン)の相対的な数に基づいてスコアを与える
-
IdenticalTokensStemmed:同一のステム処理された単語 (トークン) の相対数に基づいてスコアを付与する - ステミングとは、最も基本的な形を得るために、単語からingやedなどを取り除くことである
-
Stopwords:ストップワード(if、and、orなど)を無視し、同一単語(トークン)の相対的な数に基づいてスコアを与える
-
Fuzzy:タイプミスを考慮した2文字列の類似度のスコアを与える
-
RequestKind:ユーザーによるリクエストのタイプまたはカテゴリを記述する(現在は使用されていない)
-
TimeRelevancyStart:より最近編集/作成された文書により高いスコアを与える、検索結果の新しさに基づいてスコアを付ける機能。 現在と結果の最終編集/作成日の時間差(日数)に応じてスコアを付与します。 この機能は、Google DriveのようにアプリのAPIがそれをサポートしている場合にのみ動作する
-
TFIDF(用語頻度-逆文書頻度):これは、単語がコレクションまたはコーパス内の文書にとってどれほど重要であるかを反映する数値統計です。 文書内の単語の頻度とコレクション全体での単語の希少性に基づいてスコアを計算します。 このメソッドは、2つ以上の単語があるフレーズを検索する場合にのみ使用され、効果的である
その他のソート条件
デスクトップ/モバイルメニューのソートは、検索で以下の結果を優先します:
-
最近表示:最近ユーザーによって表示されたアイテムは、検索プロセス中にユーザーと関連性が高いため、検索結果の優先順位が高くなる
-
アプリ(OktaのようなIDP統合から):検索クエリとアプリの結果が100%一致した場合、優先順位が高くなる
-
ネイティブソート:次のアプリケーションの結果は、APIから受信した結果の順序を優先し、第三者による優先順位付け機能を利用してネイティブアプリケーションと同様の順序を表示する
-
合流
-
Jira
-
リソース:WalkMeコンテンツと統合の両方を含む結果があり、100%一致する結果がない場合は、リソースの結果を優先します。 検索結果の上に2つのリソースが表示される
キーワードで検索
エントリアルゴリズムは、タイトルとキーワードに基づいて各WalkMeアイテムのエントリを生成します。
各エントリは、検索クエリーとの関連性に基づいてスコアリングされ、それに応じて結果が表示されます。 検索結果にアイテムが表示される可能性を高めるためには、検索語と密接に一致するキーワードを持つことが重要です。 ただし、キーワードは単語単位ではなく、全体として考慮されます。 したがって、長いキーワードは論理グループまたは用語に分割する必要があります。
-
例えば、は次のように分割した方がよいである "career development", "learning system", "training system"
-
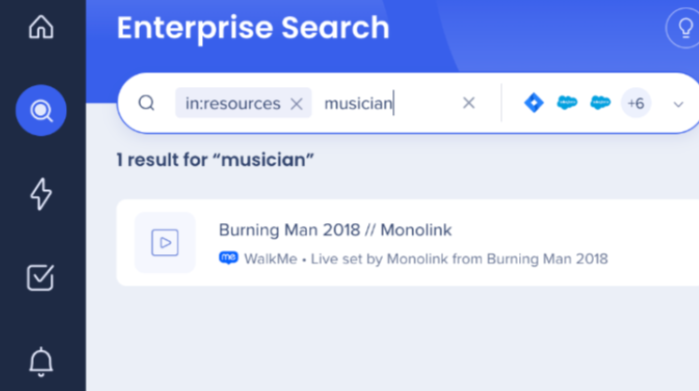
正確な一致は必要ないことに注意してください。 たとえば、キーワードを持つアイテムが、その用語の検索結果に表示されることがある musician
キーワードとして可能な各単語を分離すると、検索結果に悪影響を及ぼす可能性があります。
インデックス作成
デスクトップ/モバイルメニューは、結果をインデックス化しません。 一部のデータはクライアント側に保存されます。 例えば、最近の検索結果または最近表示されたウィジェットに表示されるデータです。
検索フローでユーザーに表示される残りのデータは、第三者のアプリAPIからリアルタイムで取得されます。
統合
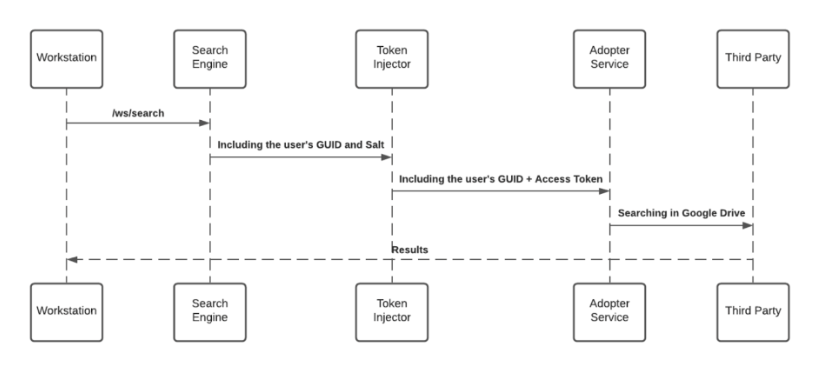
エンタープライズサーチは、サードパーティーの統合を使用して「federal search(連邦捜索)」を実装します。 デスクトップ/モバイルメニュー内の検索は、NLPエンジンと優れたユーザーエクスペリエンスをサポートするグラフデータベースに支えられています。 エンタープライズ検索は、個別に検索可能なデータベース上のサードパーティデータのインデックス化は行いません。 検索アルゴリズムを表した以下のシーケンスダイアグラムをご覧ください。
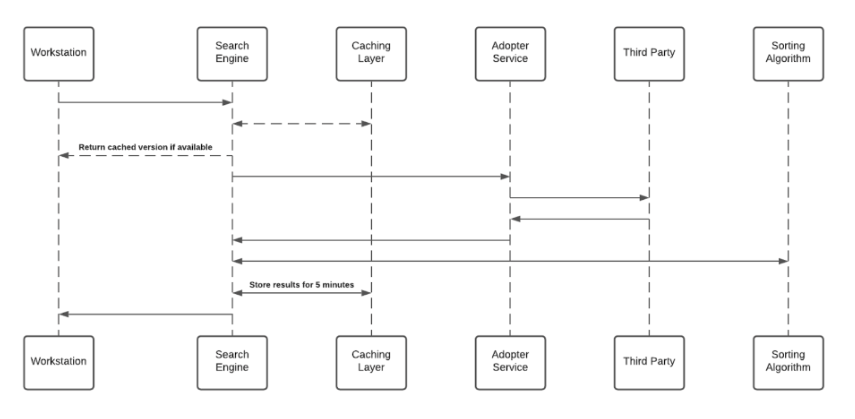
- 検索結果`はキャッシュレイヤーに5分間保存されます。
- 各アダプターサービスは、サードパーティーへのアクセスなしでは意味をなさない一意の識別子を生成し、グラフデータベースに保存します。
サードパーティーへのアクセスとトークンの更新
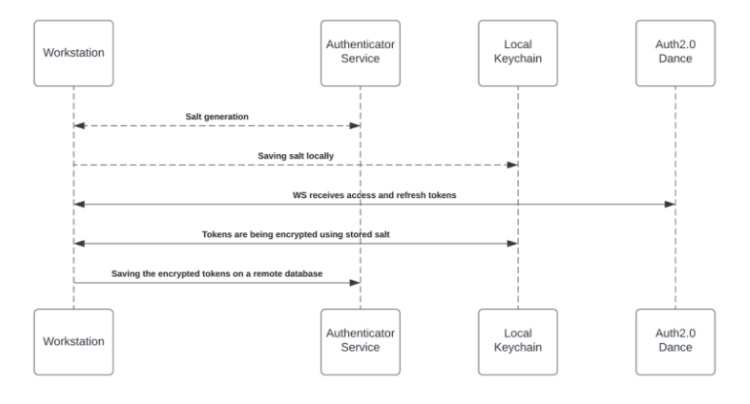
エンタープライズ検索(およびパーソナライズされたワークスペースウィジェット)を有効にするには、各従業員がデスクトップ/モバイルメニューにサードパーティにアクセスする権限を付与する必要があります。 許可プロセスにはOAuth2.0プロトコルを使用しています。 デスクトップ/モバイルメニューに新しいアクセストークンが付与されるたびに、アプリケーションはアクセストークンとリフレッシュトークンを暗号化し、リモートデータベースに保存します。
暗号化プロセスでは、最初のブートストラップ時、個々のトークン用に一意のプライベートキー(「salt」)が生成され、ローカルマシンのキーチェーンに保存されます。 saltは替えがきかず復旧もできません。なくせばアクセストークンが無効になります。 このセキュリティ対策は、極秘データにアクセスする際にIDのなりすましを防ぐために実施しています。
saltの生成と保存の流れを確認するには下図をご覧ください。
サードパーティーのコンテンツへのアクセス
サードパーティーのコンテンツにアクセスするには、ユーザーの承認が必要です。また主にMicrosoft製品で、組織管理者の承認が必要な場合もあります。 ユーザーは、デスクトップ/モバイルメニューからトリガーされたOAuth2.0同意画面を承認することで、デスクトップ/モバイルメニューに必要な権限を付与します アプリケーション(「サードパーティアプリ」)
サードパーティーアプリはサードパーティー製品で承認・検証しています。 承認プロセス完了までに、サードパーティーアプリはアクセスを許可し、検索エンジンで使用するトークンを更新してリクエストを確立します。
保存メカニズムの詳細については、上記「サードパーティーへのアクセスとトークンの更新」をご覧ください。
検索エンジンは検索中、アダプターサービスにヒットする前に、トークンインジェクター(リクエストを遂行するために関連するトークンを投入するサービス)を通じてリクエストを転送します。 ローカルのプライベートキーは、HTTPS検索リクエストを介して渡され、ランタイム復号化されます。
JWT保護
ユーザーが検索クエリを開始する際 - WalkMeエンタープライズサーチは検索フローを開始します。この検索フローは、エンドユーザーの署名フローの一部として、WalkMe IdP統合が割り当てたJWTにより保護されています。
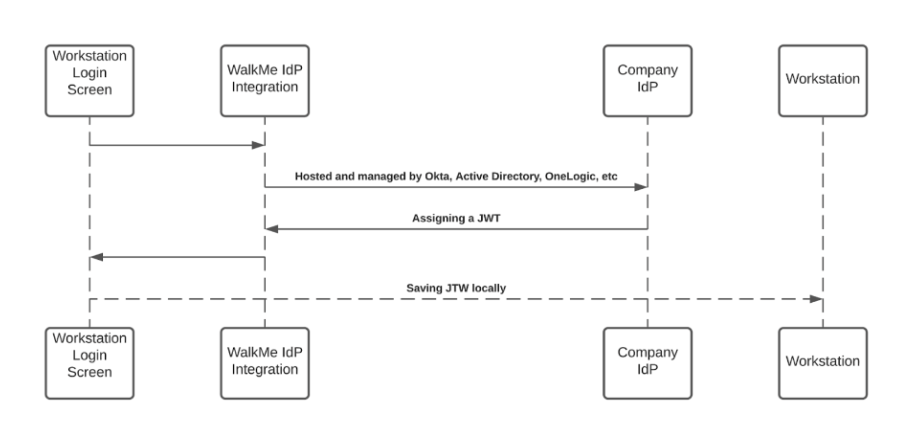
JWTは、ユーザーIDをプロキシし、各HTTPSリクエストを安全に保ちます。
デスクトップ/モバイルのメニューリクエストはすべてJWT検証によって保護されています。
統合セキュリティについては、こちらをご覧ください。
Fuzzy検索
Fuzzy検索は、検索クエリを自動的に修正します。 検索はユーザーの意図を知能的に理解し、検索クエリに些細なエラーやスペルミスがあっても関連結果を提供します。
自動修正では、次の2つのオプションをサポートしています。
ライブラリの自動修正を開く
- 構成が必要ですか? いいえ、すべてのシステムでデフォルトで動作する
- 言語の制限:英語のみ
- 文字数:3文字以上
AIベースの自動修正
- 構成が必要ですか? はい、OpenAI統合はコンソールで設定する必要がある
- 言語の制限:全言語
- 文字数:10文字以上(API Calls to OpenAIの有効活用とコスト削減のために)
誤った検索修正を回避する
ユーザーが表現を3回以上修正すれば、今後のために修正することは避けられます。 これは、次のようなシナリオを防止するためである



