概要
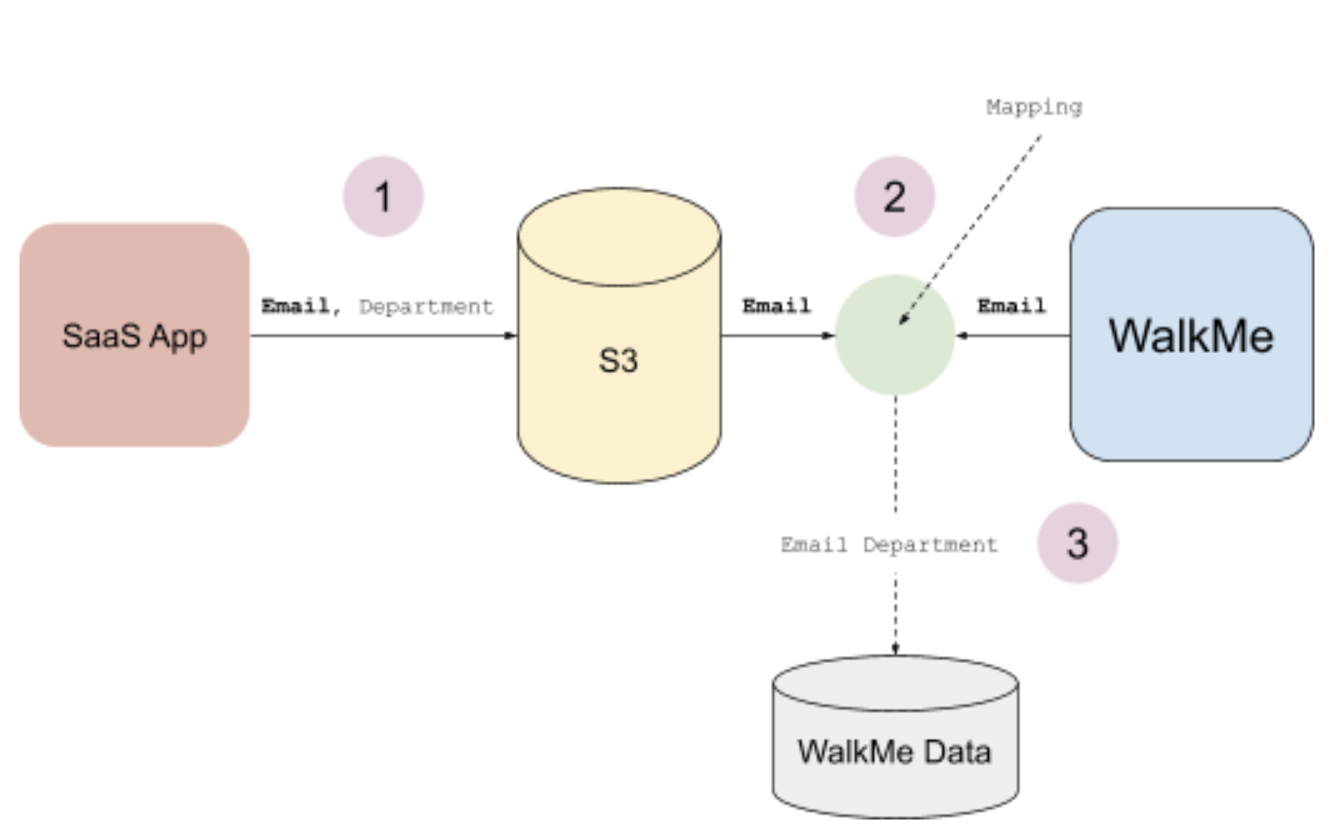
S3の受信統合では、S3上にあるサードパーティーのソフトウェアをWalkMeに接続できます。 インテグレーションでは属性を取得してWalkMeにデータを入力します。WalkMeは、外部システムからのデータを分析とコンテンツのセグメンテーションに使用します。
ユースケース
CRMの属性に基づいてターゲットを絞りWalkMeコンテンツを表示できます。
- サイトで「プレミアムユーザー」にのみシャウトアウトを表示。
- 自社の特定部門の従業員を対象にスマートウォークスルーを表示。
- Insightsとレポートビルダーで「ユーザー」フィルターカテゴリとして使用。
カスタマーサポートや成功(ServiceNow、Zendeskなど)の属性に基づいてターゲットを絞りWalkMeコンテンツを表示できます。
- 2つ以上のサポートチケットを開いたすべての顧客にNPS調査を表示。
前提条件
統合属性をWalkMeにマップするには、一意のユーザーIDを定義する必要があり、統合のサードパーティーサービスでは、S3にデータをCSVフォーマットで保存する必要があります。
次に、S3上の特定のバケットにCSVファイルを配置するとWalkMeがこのファイルを読み取り、このファイル属性情報に基づいて、エンドユーザーをターゲットにできます。
受信統合の作成
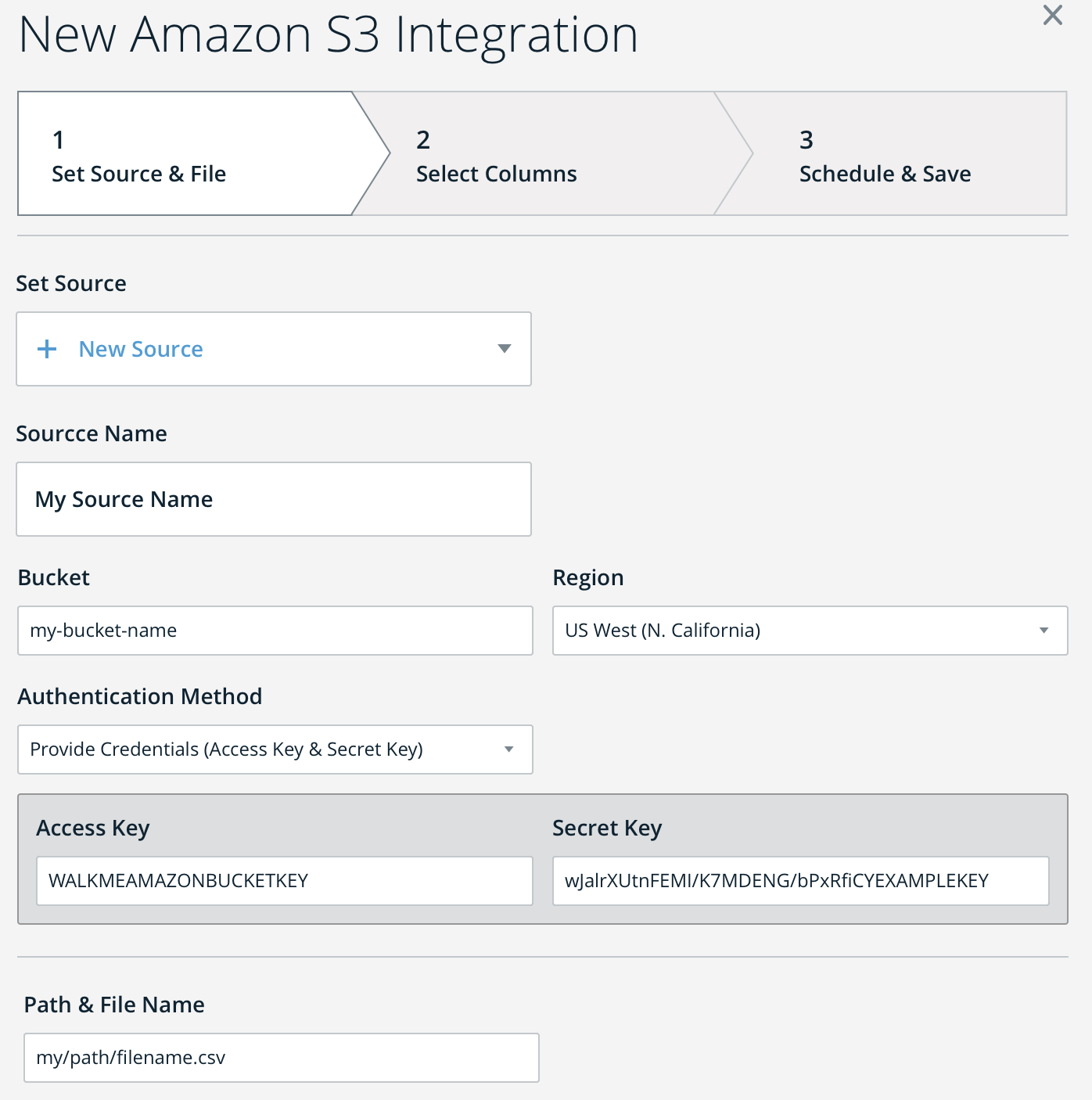
- insights.walkme.comにおいて、Insightsの[Integrations(統合)]ページで[Amazon S3 to WalkMe(Amazon S3からWalkMe)]を選択します。

- [+ New Integration(新しい統合)]をクリックして、ウィザードの手順に従って、S3バケットURL、権限とソースファイル(CSV)を設定してください。
- 注:基本認証はサポートされているため、セットアップの際に提供することができます(下記参照)。
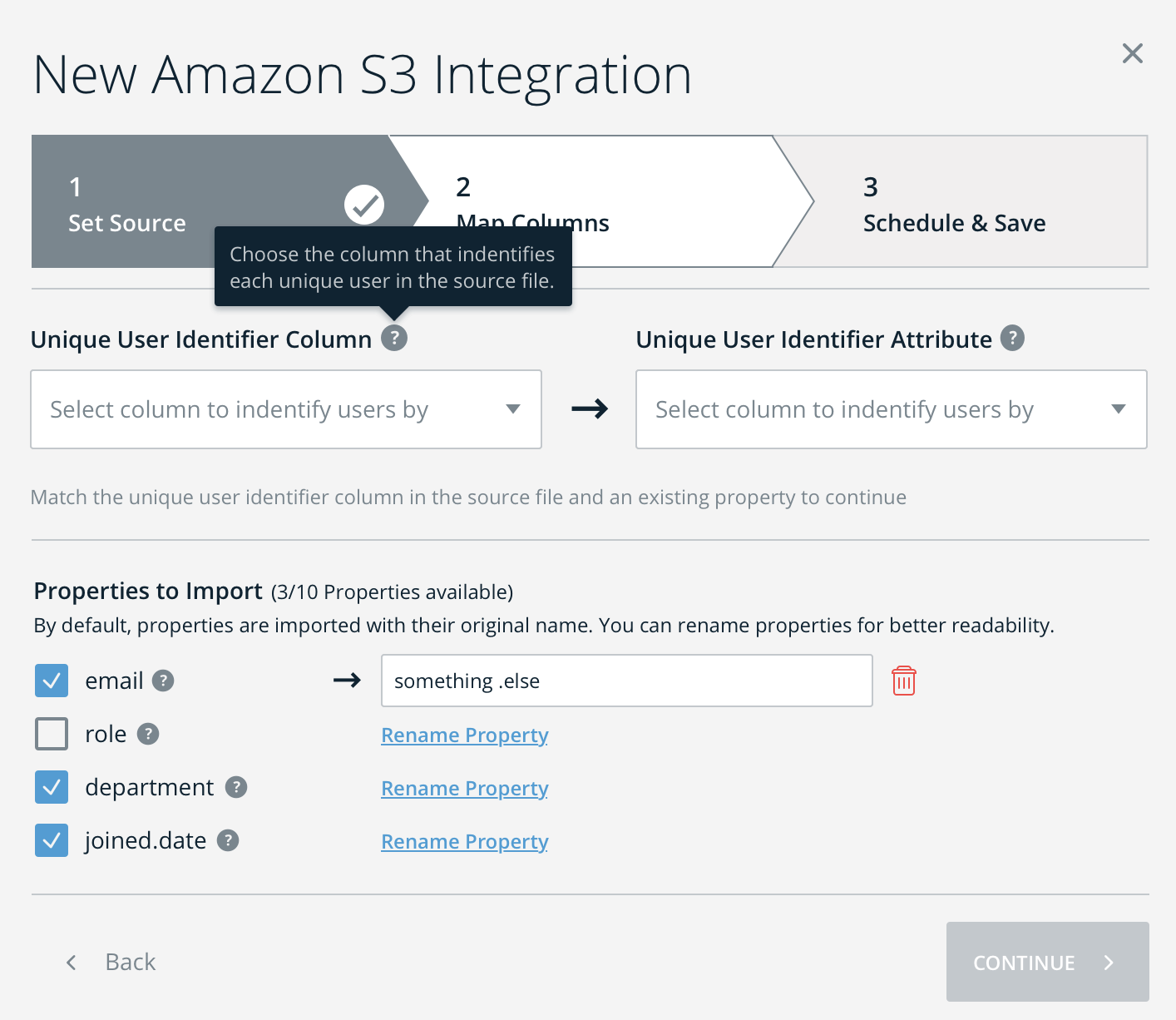
- データ検出後、ユーザー識別子をマッピングして、ターゲティングのためにWalkMeに渡す任意のプロパティ(属性)を選択します。
- 注:必要に応じて、これらのプロパティの名前を変更することができます(こちらはEditorに表示される名前です)。
- 統合を使用するための前提条件は、WalkMe Editorで一意のユーザーIDを設定することです。
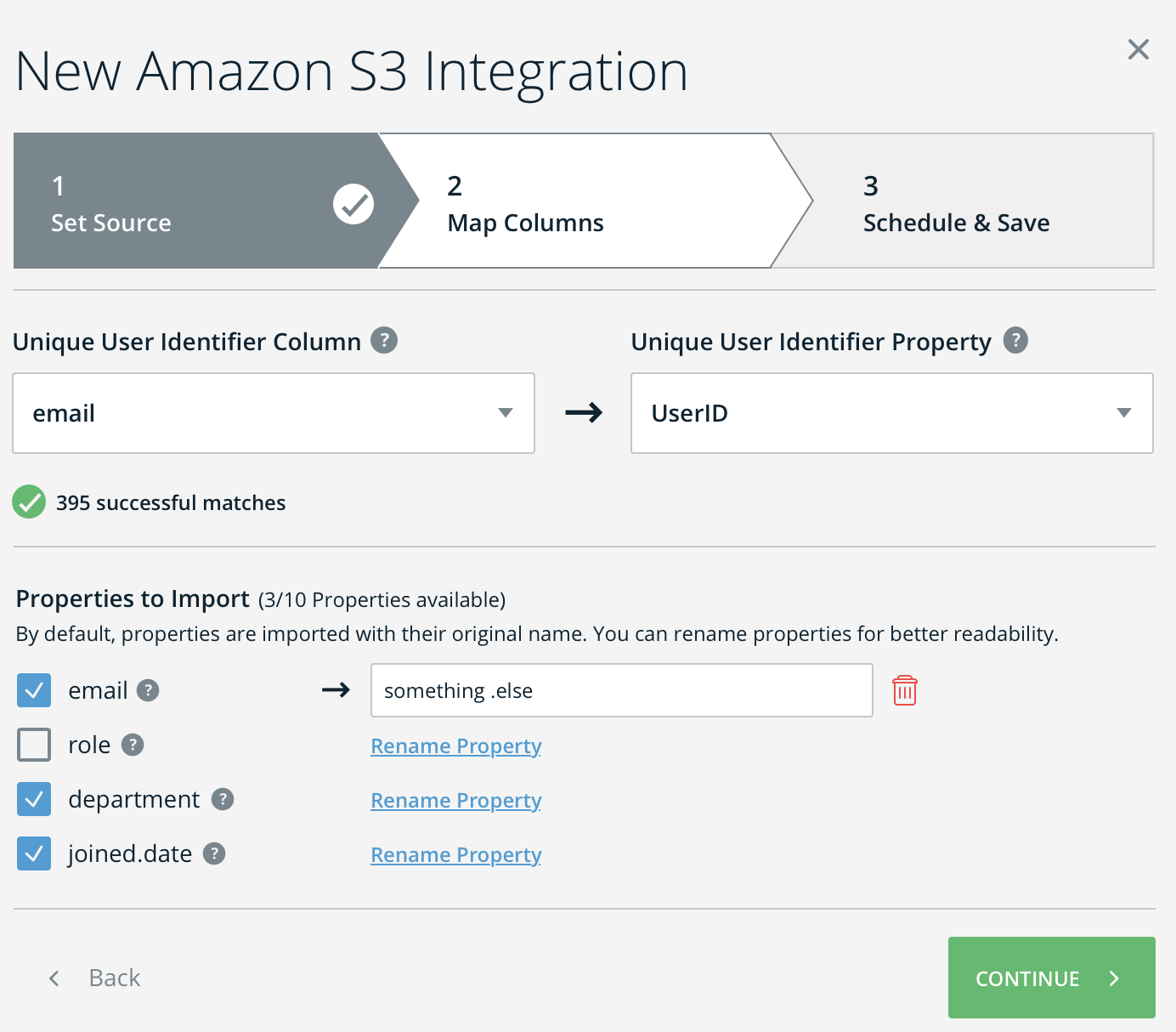
- ステップ3を完了すると、成功または失敗のメッセージを受け取ります。
- 必要に応じて、問題を解決する手順に従ってください。
- [Continue(続行)]をクリックします
- 新しいAmazon S3統合の名前を付けて、任意のインポートスケジュールを設定します(受信統合は、設定済み同期間隔に応じてS3バケットからCSVファイルを取得することで機能します)。
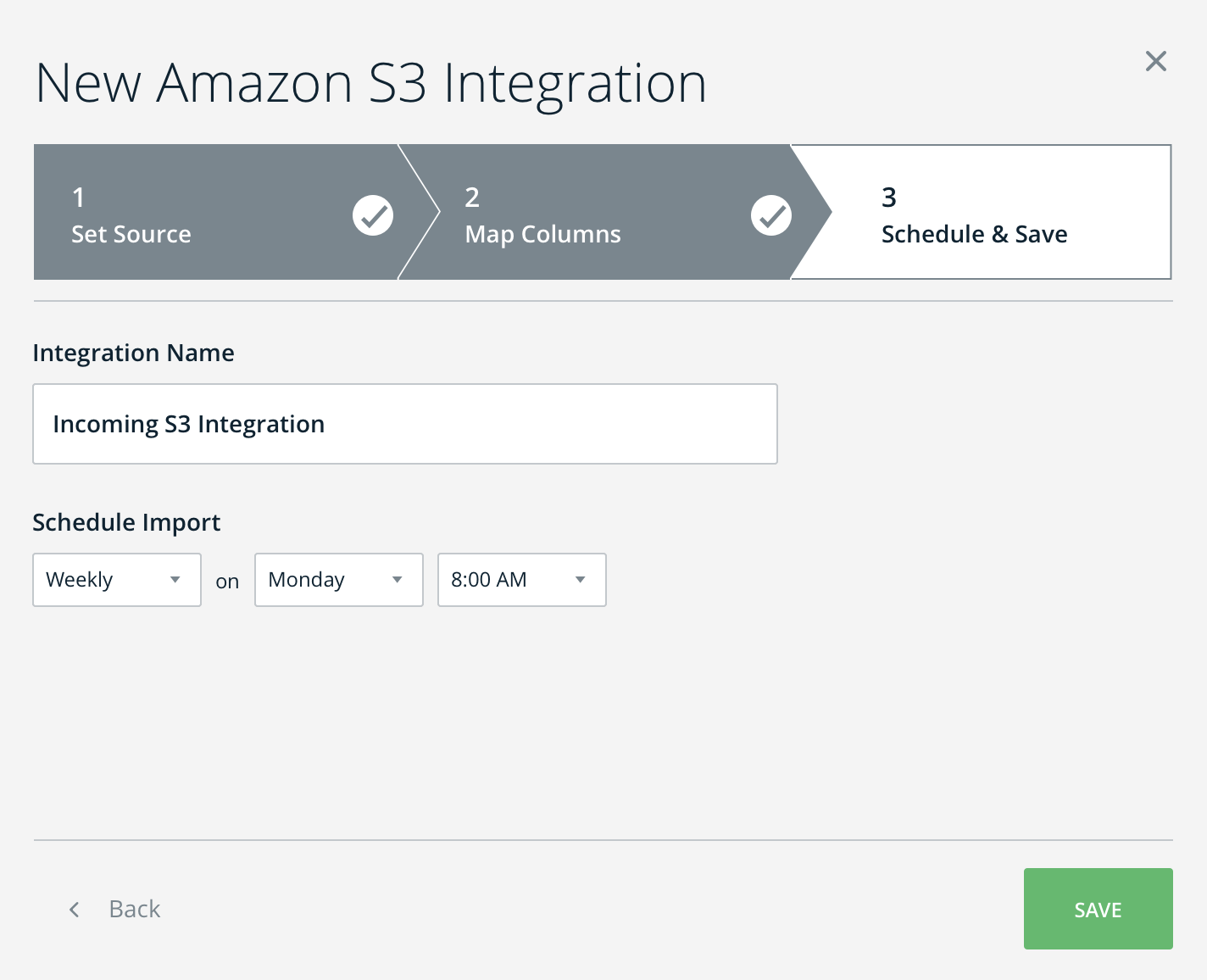
- 統合管理テーブルで新しく作成された統合を参照してください。
統合管理テーブル
このテーブルでは、統合の変更・削除と以下のプロパティの確認ができます。
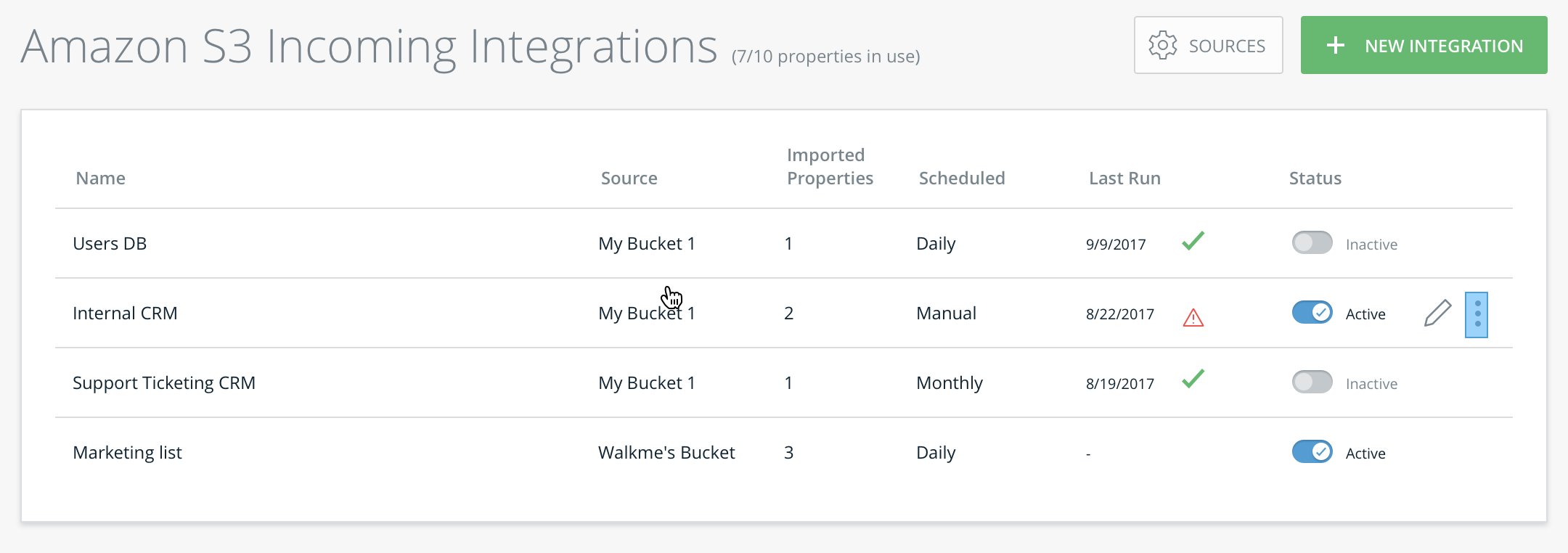
- 統合の名前
- 統合元
- 正常にインポートされたプロパティの番号
- スケジュールのインポート
- 前回の実行日
- 前回の実行が成功したかどうか(緑のチェックマークアイコンまたは赤の危険アイコンで表示)
- ステータストグル
- こちらを使用して統合を有効化または無効化します。
ベストプラクティス
- 統合の作成プロセスを完了する際、エディターでコンテンツをターゲティングする前に、受信統合テーブルで少なくとも1つの統合が正常に実行されていることを確認してください。
- 統合を変更した場合、変更は次のスケジュール実行時に反映されます。
- その前にセグメントを変更/一時停止する必要がある場合があります。
- 少ないほうが良い - WalkMeに統合する属性の総数に注意してください。
- 統合全体で合計100の属性を使用することができます。
統合データによるコンテンツのセグメント化
S3統合を正常に作成した後で、WalkMe Editor内の受信データを使用して、WalkMeコンテンツのターゲットを絞ったルールとセグメンテーションを作成できます。

注
セットアップを行っている最中に統合を作成する場合、定義した属性を正確に入力してください。
共有ファイル統合
複数の統合で共有ファイルを使用する場合、各ファイルに個別の統合を作成する必要があることに注意してください。
インサイトは、各統合のデータを処理する特定の方法を持ち、特定のファイル場所を探します。 データが処理されると、ファイルは、定義された場所内の「成功」または「失敗」ファイルの指定されたフォルダに移動されます。
2番目の統合が同じファイルにアクセスしようとすると、ファイルがすでに移動されているため、見つけることができません。 これにより、2番目の統合は失敗します。
この問題を回避するには、同じデータソースを使用している場合でも、各ファイルに個別の統合を設定します。 これにより、各統合は他の統合と競合せずに、必要なファイルにアクセスできます。
技術的なノート
- 余分なバケットを作成できません
- 代わりに、新しいサブフォルダは、セキュリティ上の理由から既存のバケット内でのみ作成できます。
- 統合ファイルの行数に制限はありません。ただし、ファイルサイズは1GBに制限されています。


