Breve Visão Geral
O WalkMe Menu Enterprise Search permite que você descubra aplicativos e recursos por meio de uma experiência de pesquisa abrangente e unificada. Ele funciona como um mecanismo de pesquisa robusto, capaz de pesquisar informações no conteúdo do WalkMe e no conteúdo de aplicativos de terceiros adicionados pela página Integrações do Console.
A pesquisa empresarial faz o seguinte:
- Fornecer descoberta de conhecimento rápida e eficiente, eliminando a necessidade de pesquisar em várias fontes de dados diferentes
- Gere resultados personalizados com tecnologia de IA, nos quais os usuários podem filtrar por aplicativo e tipo de arquivo
- Preservar a segurança dos negócios e a privacidade do usuário final, com indexação zero e respeitando as permissões de acesso
Conheça
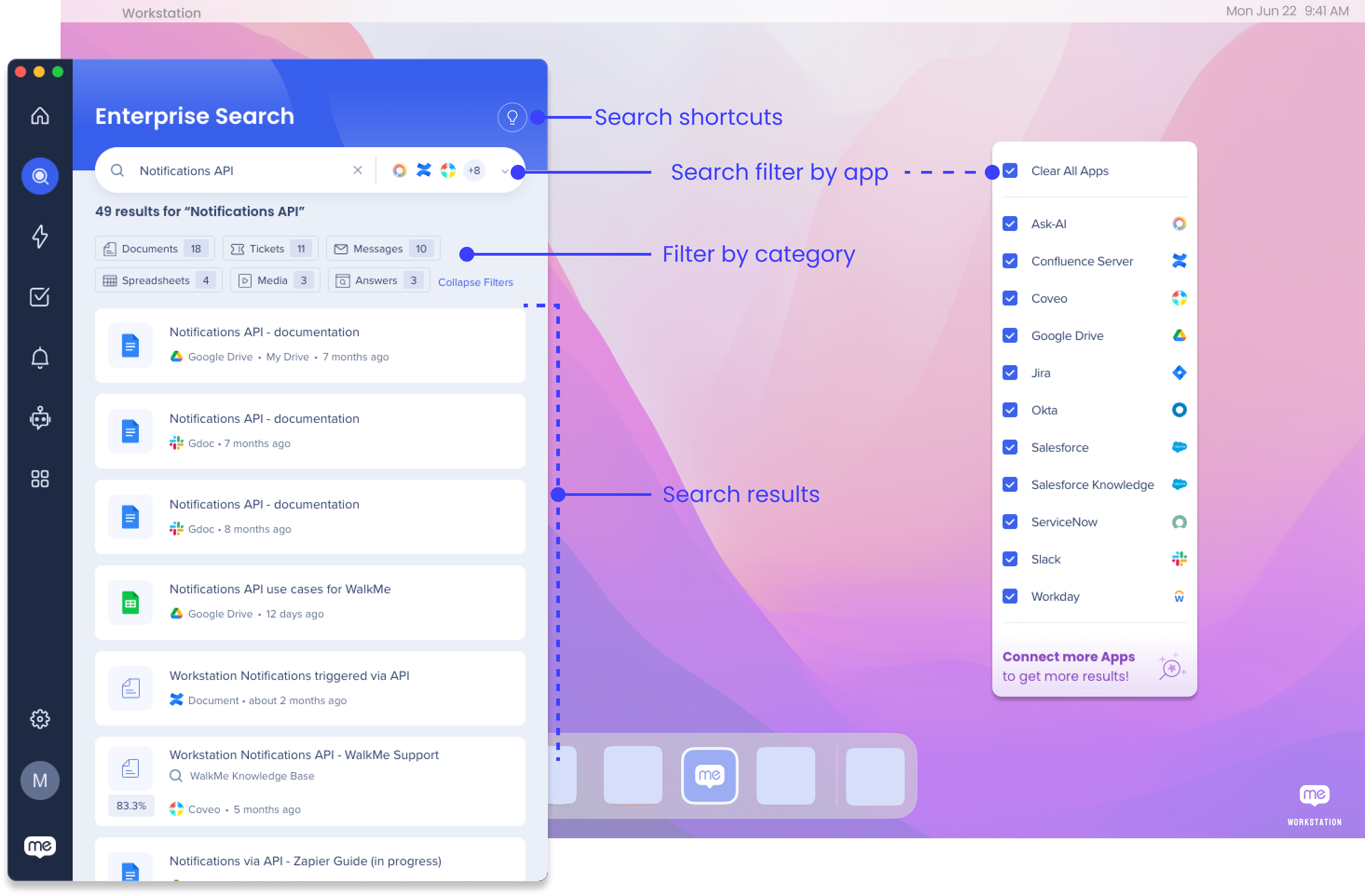
Filtrar por aplicativo
Você pode pesquisar em todos os aplicativos integrados ou filtrar a pesquisa para aplicativos específicos:
- Clique no menu suspenso na barra de pesquisa
- Selecione os aplicativos para os quais deseja filtrar a pesquisa
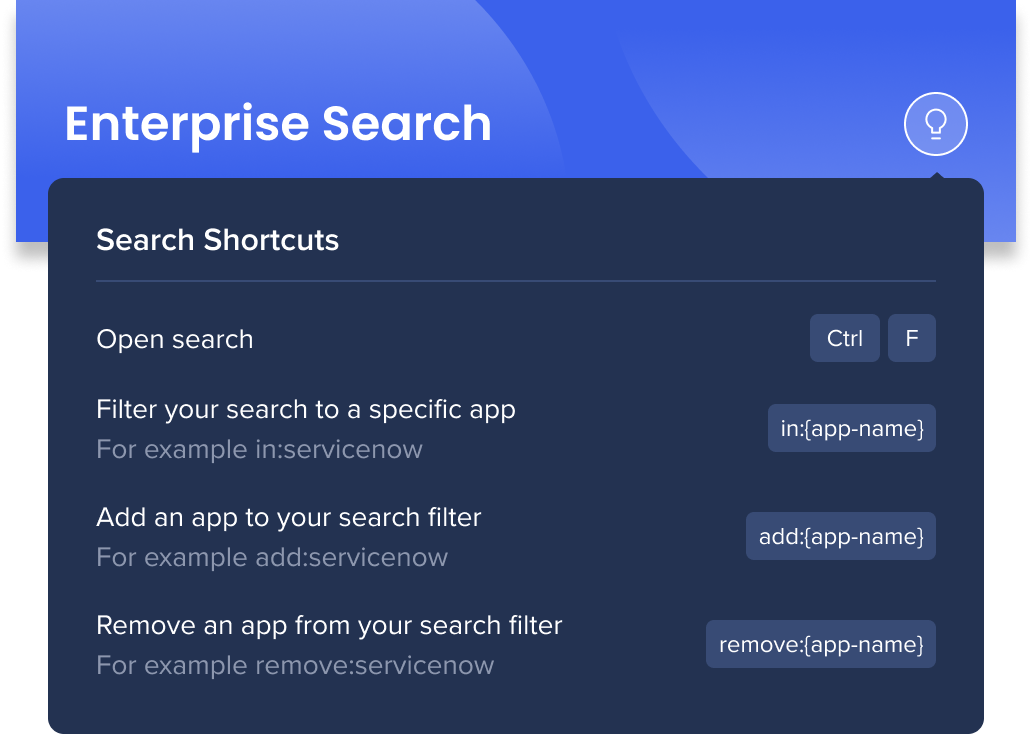
Atalhos de pesquisa
Há também atalhos rápidos de teclado que você pode usar para ajustar seus aplicativos sem alterar o filtro de pesquisa.
- Abrir a pesquisa: pressione Ctrl/Cmd+F
- Filtre a pesquisa para um aplicativo específico: digite:{app name}
- Por exemplo, se você tiver todos os aplicativos selecionados no filtro e digitar:servicenow, você verá apenas os resultados do ServiceNow
- Remova o atalho para voltar ao filtro
- Adicione um aplicativo ao filtro de pesquisa: digite add:{app name}
- Por exemplo, se você filtrou a pesquisa para alguns aplicativos e quiser adicionar o ServiceNow sem ajustar o filtro, digite add:servicenow
- Remova o atalho para voltar ao filtro
- Remova um aplicativo do filtro de pesquisa: digite remove:{app name}
- Por exemplo, se você não quiser mais ver resultados para o ServiceNow, digite remove:servicenow
- Remova o atalho para voltar ao filtro
Filtrar por categoria
Quando os resultados da pesquisa são carregados, há filtros de categoria adicionais que são exibidos. Isso permite especificar ainda mais sua pesquisa para o tipo de conteúdo.
Isso é útil, por exemplo, se você sabe que está procurando um documento, mas não se lembra de qual aplicativo ele é. Basta clicar no botão Documento e a pesquisa será filtrada apenas para documentos em todos os aplicativos no filtro de pesquisa.
O filtro de categoria mostra apenas o tipo de conteúdo que apareceu nos resultados da pesquisa. Portanto, se nenhum dos resultados for um documento, a categoria de documento não será uma opção.

Clique aqui para obter uma lista de todas as categorias possíveis...
- Documento
- Ticket
- Mensagem
- Planilha
- Mídia
- Respostas
- ActionBot
- Recurso
- Código
- Ofertas
- Oportunidades
- Contas
- Eventos
- Relatórios
- Apps
- Apresentações
- Leads
- Site
Resultados da pesquisa
Os resultados da pesquisa mostrarão o nome do conteúdo e do aplicativo do qual ele é. Clicar em um resultado o colocará no widget Visualizados Recentemente na sua página inicial, para que você possa voltar rapidamente a ele.
Pesquisar em qualquer idioma
O Enterprise Search oferece suporte a todos os idiomas. Isso significa que você pode pesquisar usando o idioma preferido, tornando mais fácil e rápido encontrar as informações necessárias.
Correção automática
Os usuários não precisam mais se preocupar com ortografia precisa ou correspondências exatas. Nosso recurso de pesquisa entenderá de forma inteligente a intenção dos usuários e fornecerá os resultados mais relevantes, mesmo que haja pequenos erros ou erros ortográficos na consulta de pesquisa.
Veja como isso funciona:
- Biblioteca de código aberto (sem IA): uma biblioteca de código aberto corrigirá erros comuns de gramática e vocabulário nas consultas de pesquisa. As autocorreções da biblioteca de código aberto suportam apenas inglês.
- Integração OpenAI: a integração com o OpenAI levará as correções de consultas de pesquisa ao próximo nível usando algoritmos baseados em IA. As correções automáticas do OpenAI oferecem suporte a todos os idiomas.
Classificação dos resultados da pesquisa
Fluxo de classificação de resultados
A Pesquisa Empresarial usa um Serviço de Classificação que classifica os resultados de acordo com sua relevância. Como o serviço de classificação executa a classificação:
-
Um usuário pesquisa um termo no aplicativo de menu para desktop/dispositivo móvel
-
O serviço de pesquisa obtém o termo e solicita o serviço de cada aplicativo conectado em tempo real
-
Pesquisa de serviço do aplicativo conectado para esse termo, cada um com sua própria chamada de API e implementação
-
O serviço de pesquisa obtém todos os resultados da pesquisa de todos os aplicativos conectados
-
O serviço de pesquisa chama o serviço de classificação com os resultados
-
O serviço de classificação classifica/ordena os resultados e envia os resultados classificados/ordenados de volta ao serviço de pesquisa
-
O serviço de pesquisa retorna os resultados ao aplicativo de menu para desktop/dispositivo móvel
Classificação dos métodos de pontuação
O serviço Classificador usa 9 métodos de pontuação diferentes, incluindo stemming, fuzziness e NLP, além da distância básica Levenshtein. Cada resultado obtém 9 pontuações (uma por método), variando de 0 a 1, para definir a prioridade.
-
LevenshteinFast: algoritmo computacional usado para calcular a distância Levenshtein entre duas strings, que é uma medida do número mínimo de edições de caracteres únicos (inserções, exclusões ou substituições) necessárias para transformar uma string na outra
-
JaroWinkler: medida de similaridade de strings usada para comparar a semelhança entre duas strings
-
IdenticalTokens: concede uma pontuação com base no número relativo de palavras idênticas (tokens)
-
IdenticalTokensStemmed: concede uma pontuação com base no número relativo de palavras idênticas com radical extraído (tokens) - o stemming é o processo de remoção de ing, ed, etc. de uma palavra para obter sua forma mais básica
-
Palavras de parada: concede uma pontuação com base no número relativo de palavras idênticas (tokens), ignorando palavras de parada (se, e etc.)
-
Fuzzy: concede uma pontuação pela similaridade de 2 strings, levando em consideração erros de digitação
-
RequestKind: descreve o tipo ou categoria de solicitação feita por um usuário (atualmente não em uso)
-
TimeRelevancyStart: uma função que classifica os resultados da pesquisa com base na recência, dando uma pontuação mais alta aos documentos editados/criados recentemente. Ele concede uma pontuação de acordo com a diferença de tempo (dias) entre o momento atual e a data da última edição/criação do resultado. Essa função só funciona se a API do aplicativo for compatível, como no Google Drive
-
TFIDF (Frequência de Termo-Frequência Inversa do Documento): é uma estatística numérica que reflete a importância de uma palavra para um documento em uma coleção ou corpus. Calcula uma pontuação com base na frequência da palavra no documento e na raridade da palavra na coleção inteira. Esse método só é usado e eficaz ao pesquisar frases com mais de duas palavras
Outras condições de classificação
O classificador no Menu desktop/móvel dá prioridade aos seguintes resultados na pesquisa:
-
Visualizados recentemente: os itens que foram visualizados recentemente pelo usuário recebem uma prioridade mais alta nos resultados da pesquisa, pois são mais propensos a serem mais relevantes para o usuário durante o processo de pesquisa
-
Aplicativos (de integrações do IDP, como Okta): quando houver uma correspondência de 100% entre a consulta de pesquisa e o resultado do aplicativo, ele receberá prioridade mais alta
-
Classificação nativa: os resultados dos seguintes aplicativos priorizam a ordem dos resultados recebidos das APIs e aproveitam os recursos de priorização de terceiros para exibir uma ordem semelhante aos aplicativos nativos
-
Confluence
-
Jira
-
Recursos: nos casos em que houver resultados contendo conteúdo do WalkMe e integrações, e nenhum resultado tiver uma correspondência de 100%, os resultados dos recursos serão priorizados. Dois recursos são exibidos na parte superior dos resultados da pesquisa
Pesquisar por palavras-chave
Nosso algoritmo de entrada gera entradas para cada item do WalkMe com base no título e palavras-chave.
-
Se um item não tiver palavras-chave, apenas uma entrada será criada usando o título
-
Se um item tiver palavras-chave, entradas adicionais serão geradas para cada palavra-chave, incluindo o título e a própria palavra-chave
Cada entrada é pontuada com base na sua relevância para a consulta de pesquisa e os resultados são exibidos de acordo. Para aumentar as chances de um item aparecer nos resultados da pesquisa, é importante ter palavras-chave que correspondam aos termos de pesquisa. No entanto, as palavras-chave não são consideradas palavra por palavra, mas como um todo. Portanto, palavras-chave longas devem ser divididas em grupos lógicos ou termos.
-
Por exemplo, seria melhor dividir como "career development", "learning system", "training system"
-
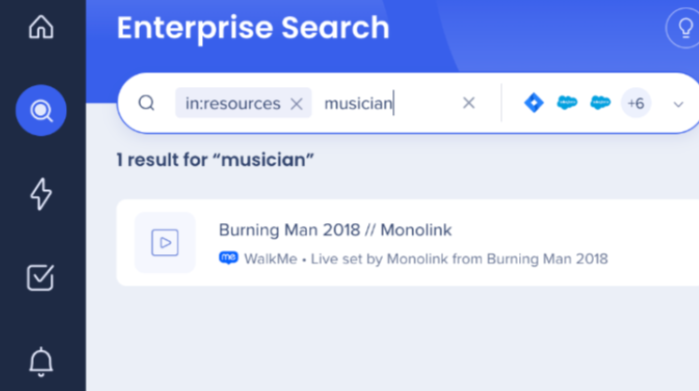
Observe que não é necessária uma correspondência exata. Por exemplo, um item com a palavra-chave ainda pode aparecer nos resultados da pesquisa para o termo musician
Separar cada palavra possível como palavra-chave pode prejudicar os resultados da pesquisa.
-
Por exemplo, a palavra-chave corresponderá a termos como , e assim por diante, se cada palavra for considerada como uma palavra-chave separada. Portanto, é melhor ser mais preciso, como mencionado acima, para reduzir falsos positivos e ainda assim ser útil para pesquisas parciais
Indexação
O menu desktop/dispositivo móvel não indexa resultados. Alguns dados são armazenados no lado do cliente. Por exemplo, os dados que aparecem nos Resultados da pesquisa recente ou no widget Visualizado recentemente.
O restante dos dados exibidos ao usuário no fluxo de pesquisa é trazido em tempo real das APIs de aplicativos de terceiros.
Integrações
O Enterprise Search usa integrações de terceiros para implementar uma "pesquisa federal". As pesquisas no menu desktop/dispositivo móvel são suportadas por um mecanismo de PNL e um banco de dados gráfico que oferece suporte a uma ótima experiência do usuário. A Pesquisa Empresarial não indexa dados de terceiros em um banco de dados pesquisável de forma independente. O diagrama de sequência abaixo descreve o algoritmo de pesquisa:
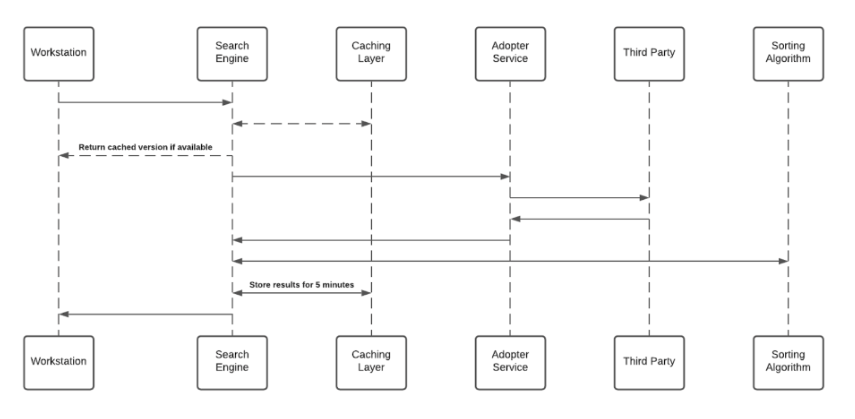
- A camada de cache salva os resultados por um período de cinco minutos
- Cada Serviço Adotante cria um identificador exclusivo para os resultados, o que não faz sentido sem acesso ao terceiro, e o armazena no banco de dados de gráficos.
Tokens de acesso e atualização de terceiros
Para ativar a Pesquisa Corporativa (e os widgets Personalizados do Espaço de Trabalho), cada funcionário deve conceder permissão do menu desktop/dispositivo móvel para acessar o serviço de terceiros. O processo de concessão está usando o protocolo OAuth2.0. Sempre que um novo token de acesso for concedido ao menu desktop/dispositivo móvel, o aplicativo criptografará os tokens de acesso e atualização e os armazenará em um banco de dados remoto.
O processo de criptografia inclui uma chave privada exclusiva ("salt") que é gerada para cada indivíduo no primeiro bootstrap e armazenada no Chaveiro da máquina local. O sal é insubstituível e não pode ser restaurado – perdê-lo faz com que os tokens de acesso sejam anulados. Essa medida de segurança está sendo tomada para eliminar a falsificação de identidade ao acessar dados altamente confidenciais.
Consulte o diagrama abaixo para rever o fluxo de geração e armazenamento de sal.
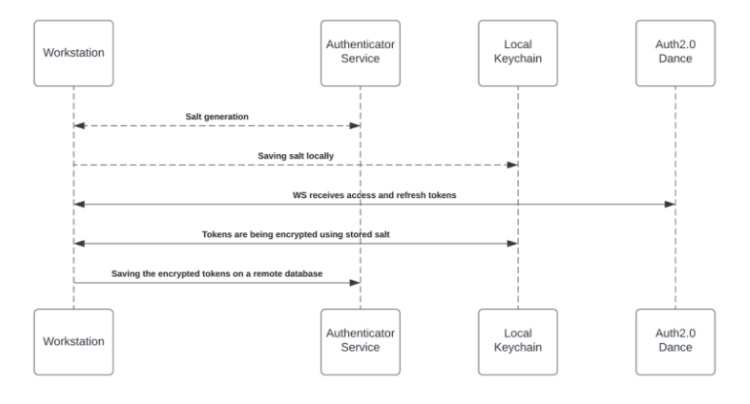
Acessando conteúdo de terceiros
O acesso a conteúdo de terceiros requer o consentimento do usuário e, em alguns casos, principalmente em produtos Microsoft, o consentimento do administrador da organização. Os usuários concedem ao menu desktop/dispositivo móvel a permissão necessária aprovando uma tela de consentimento OAuth2.0 que está sendo acionada por eles no menu desktop/dispositivo móvel. aplicativo ("Aplicativos de terceiros").
Os aplicativos de terceiros estão sendo aprovados e verificados por produtos de terceiros. No final do processo de concessão, os aplicativos de terceiros fornecem tokens de acesso e atualização que são usados pelo mecanismo de pesquisa para estabelecer as solicitações.
Consulte a seção Tokens de Acesso e Atualização de Terceiros acima para obter mais informações sobre o mecanismo de armazenamento.
Ao pesquisar, o mecanismo de pesquisa encaminha a solicitação, antes de atingir o Adopter Service, por meio do Token Injector; um serviço que injeta os tokens relevantes para concluir a solicitação. A chave privada local está sendo entregue na solicitação HTTPS de pesquisa para descriptografia no tempo de execução.
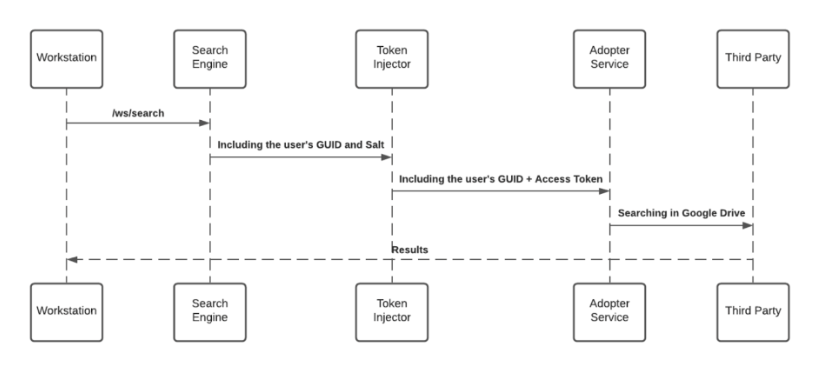
Proteção JWT
Quando um usuário inicia uma consulta de pesquisa – a pesquisa corporativa do WalkMe inicia um fluxo de pesquisa que está sendo protegido por um JWT atribuído pela integração do WalkMe IdP, como parte do fluxo de assinatura do usuário:
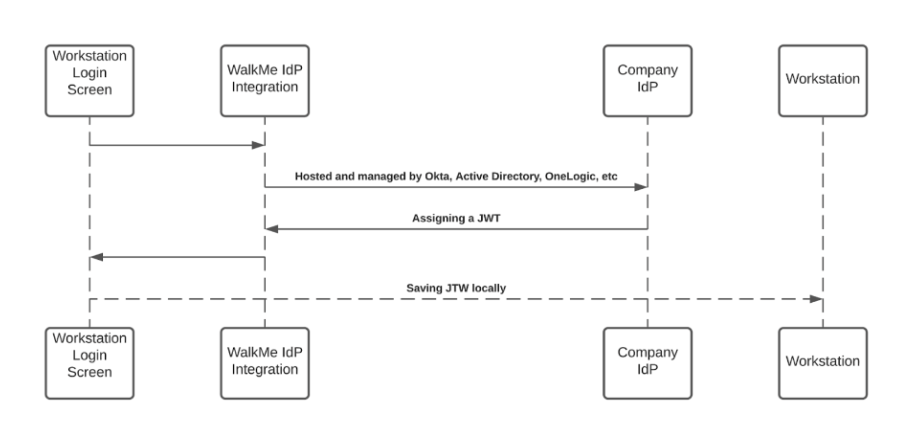
O JWT está representando a identidade do usuário e mantendo qualquer solicitação HTTPS segura e individual.
Todas as solicitações de menu para desktop/dispositivos móveis estão protegidas por uma validação JWT.
Leia mais sobre segurança de integração aqui.
Pesquisa Fuzzy
O Fuzzy Search fornece uma correção automática para consultas de pesquisa. A pesquisa entende de forma inteligente a intenção dos usuários e fornece resultados relevantes, mesmo que existam pequenos erros ou erros de ortografia nas consultas de pesquisa.
Suportamos duas opções de correção automática:
Correção automática da Open Library
- Configuração necessária? Não, funciona por padrão para todos os sistemas
- Limitações de idioma: somente inglês
- Número de caracteres: 3 ou mais
Correção automática baseada em IA
- Configuração necessária? Sim, a integração OpenAI deve ser configurada no Console
- Limitações de idioma:Todos os idiomas
- Número de caracteres: 10 ou mais (isso é para usar efetivamente as chamadas de API para OpenAI e reduzir custos)
Evite correções de pesquisa erradas
Se os usuários corrigirem uma expressão 3 vezes ou mais, isso evitará corrigi-la no futuro. Isso é para evitar cenários como os seguintes-



