Aperçu rapide
La Recherche Enterprise Menu WalkMe vous permet de découvrir des applications et des ressources grâce à une expérience de recherche unifiée et complète. Cela fonctionne comme un moteur de recherche robuste capable de rechercher des informations à la fois dans le contenu et le contenu de WalkMe dans les applications tierces qui ont été ajoutées via la page Intégrations de la console.
La recherche d'entreprise permet les éléments suivants :
- Fournir une découverte de connaissances rapide et efficace, éliminant la nécessité de rechercher plusieurs sources de données disparates
- Générer des résultats personnalisés et alimentés par l'IA où les utilisateurs peuvent filtrer par application et par type de fichier
- Préserver la sécurité des entreprises et la confidentialité des utilisateurs finaux, avec l'indexation zéro et le respect des autorisations d'accès
En savoir plus
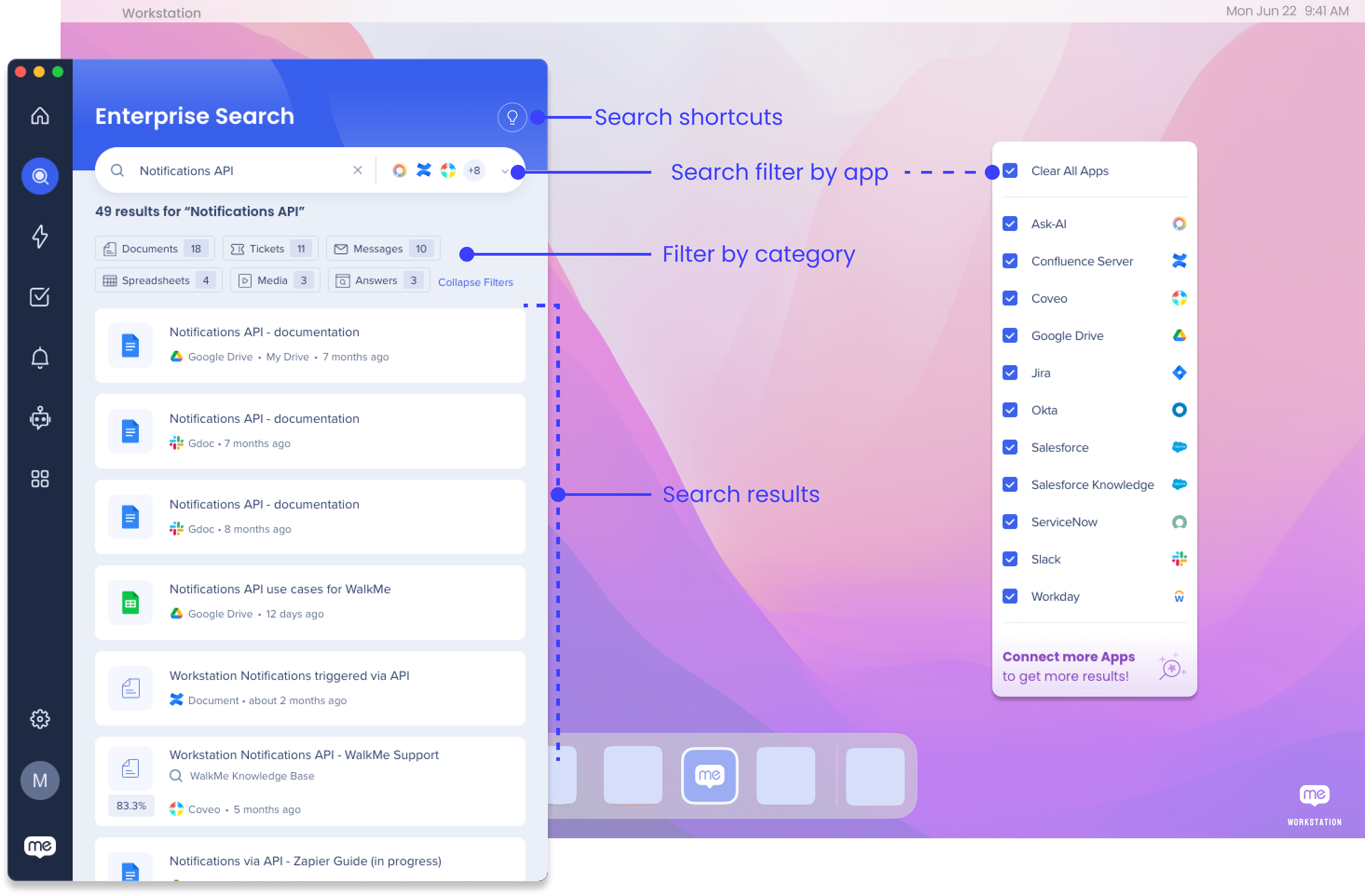
Filtrer par application
Vous pouvez rechercher dans toutes vos applications intégrées ou filtrer la recherche dans des applications spécifiques :
- Cliquez sur le menu déroulant dans la barre de recherche
- Sélectionnez les applications auxquelles vous souhaitez filtrer la recherche
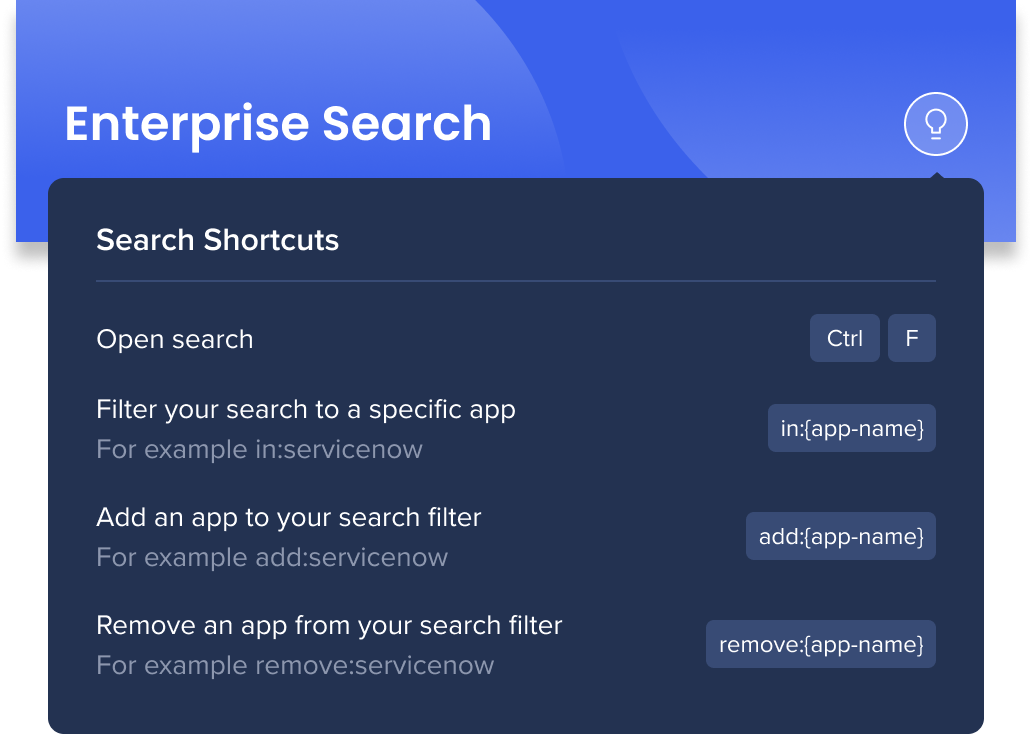
Recherche de raccourcis
Il existe également des raccourcis clavier rapides que vous pouvez utiliser afin d'ajuster vos applications sans changer le filtre de recherche.
- Recherche ouverte : Appuyez sur Ctrl/Cmd+F
- Filtrer votre recherche dans une application spécifique : Tapez in:{app name}
- Par exemple, si vous avez toutes les applications sélectionnées dans le filtre et tapez in:servicenow, vous verrez les résultats de ServiceNow
- Supprimez le raccourci pour retourner à votre filtre
- Ajoutez une application à votre filtre de recherche : Tapez add:{app name}
- Par exemple, si vous avez filtré votre recherche dans quelques applications et que vous souhaitez ajouter ServiceNow sans ajuster votre filtre, tapez add:servicenow
- Supprimez le raccourci pour retourner à votre filtre
- Supprimez une application de votre filtre de recherche : Tapez remove:{app name}
- Par exemple, si vous ne souhaitez plus voir les résultats pour ServiceNow, tapez remove:servicenow
- Supprimez le raccourci pour retourner à votre filtre
Filtrer par catégorie
Lorsque vos résultats de recherche se chargent, il existe des filtres de catégorie qui apparaissent. Cela vous permet de spécifier votre recherche dans le type de contenu.
Cela est pratique, par exemple, si vous savez que vous recherchez un document, mais vous ne vous souvenez pas de l'application à laquelle il appartient. Cliquez simplement sur le bouton Document pour que la recherche ne porte que sur les documents de toutes les applications dans votre filtre de recherche.
Le filtre de catégorie affiche le type de contenu qui est apparu dans les résultats de la recherche. Donc, si aucun des résultats ne sont un document, la catégorie de document ne sera pas un choix.

Cliquez ici pour une liste de toutes les catégories possibles...
- Documentez
- Ticket
- Message
- Feuille de calcul
- Médias
- Réponses
- ActionBot
- Ressource
- Code
- Offres
- Opportunités
- Comptes
- Événements
- Rapports
- Apps
- Présentations
- Leads ou prospects
- Site Web
Résultats de recherche
Vos résultats de recherche vous montreront le nom de contenu et l'application à laquelle il appartient. En cliquant sur un résultat, vous le placerez dans le Widget récemment consulté sur votre page d'accueil afin que vous puissiez y revenir.
Rechercher dans n'importe quelle langue
Enterprise Search prend en charge toutes les langues. Cela signifie que vous pouvez effectuer des recherches en utilisant votre langue préférée, ce qui rend plus facile et plus rapide la recherche des informations dont vous avez besoin.
Correction automatique
Les utilisateurs n'ont plus à se soucier de l'orthographe ou des correspondances exactes. Notre capacité de recherche comprendra intelligemment leur intention et fournira les résultats les plus pertinents, même s'il y a des erreurs mineures ou des fautes d'orthographe dans la requête de recherche.
Voici comment cela fonctionne :
- Bibliothèque open source (non-IA) : une bibliothèque open source corrige les erreurs de grammaire et de vocabulaire courantes dans les requêtes de recherche. Les autocorrections de la bibliothèque open source prennent en charge l'anglais uniquement.
Trier les résultats de recherche
Flux de tri des résultats
La recherche d'entreprise utilise un service de tri qui trie les résultats en fonction de leur pertinence. Comment le service de tri fonctionne :
-
Un utilisateur recherche un terme dans l'application de menu bureau/mobile
-
Le service de recherche obtient le terme et les appels pour le service de chaque application connectée en temps réel
-
Le service de recherche de l'application connectée pour ce terme, chacune avec son propre appel d'API et sa propre implémentation
-
Le service de recherche reçoit tous les résultats de recherche de toutes les applications connectées
-
Le service de recherche appelle le service de tri avec les résultats
-
Le service de tri trie ou commande les résultats et renvoie les résultats triés/commandés au service de recherche
-
Le service de recherche renvoie les résultats à l'application du menu bureau/mobile
Méthodes de notation de tri
Le service de tri utilise 9 méthodes de notation différentes, y compris l'indexation par radicaux, le flou et le NLP, en plus de la simple distance de Levenshtein. Chaque résultat obtient 9 scores (un par méthode), allant de 0 à 1, afin de définir la priorité.
-
LevenshteinFast : Algorithme informatique utilisé pour mesurer la distance de Levenshtein entre deux chaînes, cette dernière est une mesure du nombre minimum de modifications à un seul caractère (insertions, suppressions ou substitutions) nécessaires pour transformer une chaîne en l'autre
-
JaroWinkler : Mesure de la similarité de chaîne qui est utilisée pour comparer la similarité entre deux chaînes
-
IdenticalTokens : accorde un score basé sur le nombre relatif de mots identiques (jetons)
-
IdenticalTokensStemmed : accorde un score basé sur le nombre relatif de mots identiques tiges (jetons) - le stemming est le processus de suppression de ing, ed, etc. d'un mot afin d'obtenir sa forme la plus basique
-
Stopwords : accorde un score basé sur le nombre relatif de mots identiques (jetons) tout en ignorant les mots d'arrêt (si, et, ou etc.)
-
Fuzzy : accorde un score pour la similarité de 2 chaînes tout en prenant en compte les fautes de frappe
-
RequestKind : décrit le type ou la catégorie d'une demande effectuée par un utilisateur (actuellement non utilisé)
-
TimeRelevancyStart : une fonction qui note les résultats de recherche en fonction de leur récence, donnant un score plus élevé aux documents plus récemment modifiés/créés. Elle accorde un score en fonction de la différence de temps (jours) entre maintenant et la dernière date de modification/création du résultat. Cette fonction ne fonctionne que si l'API de l'application la prend en charge, comme dans Google Drive
-
TFIDF (Term Frequency-Inverse Document Frequency) : Il s'agit d'une statistique numérique qui reflète l'importance d'un mot pour un document dans une collection ou un corpus. Elle détermine un score en fonction de la fréquence du mot dans le document et de la rareté du mot dans l'ensemble de la collection. Cette méthode est uniquement utilisée et efficace lors de la recherche de phrases avec plus de deux mots
Autres modalités de tri
Le trieur dans le menu de bureau/mobile donne la priorité aux résultats suivants dans la recherche :
-
Récemment vus : les éléments qui ont été récemment vus par l'utilisateur obtiennent une priorité plus élevée dans les résultats de recherche, car ils sont plus susceptibles d'être plus pertinents pour l'utilisateur pendant le processus de recherche
-
Applications (à partir d'intégrations IDP comme Okta) : en cas de correspondance à 100 % entre la requête de recherche et le résultat d'une application, celle-ci recevra une priorité plus élevée.
-
Tri natif : les résultats des applications suivantes donnent la priorité à l'ordre des résultats reçus de l'API et exploitent les capacités de priorisation des tiers pour afficher un ordre similaire aux applications natives
-
Confluence
-
Jira
-
Ressources : dans les cas où des résultats intègrent à la fois des contenus et des intégrations WalkMe et qu'aucun résultat ne correspond à 100 %, les résultats des ressources seront prioritaires. Deux ressources sont affichées en haut des résultats de recherche
Recherche par mots-clés
Notre algorithme de saisie génère des entrées pour chaque élément WalkMe en fonction de leur titre et de leurs mots-clés.
-
Si un élément n'a pas de mots-clés, une seule entrée est créée à l'aide de son titre
-
Si un élément a des mots-clés, des entrées supplémentaires sont générées pour chaque mot-clé, y compris le titre et le mot-clé lui-même
Chaque entrée est notée en fonction de sa pertinence pour la requête de recherche et les résultats sont affichés en fonction. Il est important d'avoir des mots-clés qui correspondent étroitement aux termes de recherche pour augmenter les chances qu'un élément apparaisse dans les résultats de recherche. Cependant, les mots-clés ne sont pas pris en compte mot par mot, mais dans leur ensemble. Ainsi, les mots-clés longs doivent être divisés en groupes ou en termes logiques.
-
Par exemple, serait mieux divisé en tant que "career development", "learning system", "training system"
-
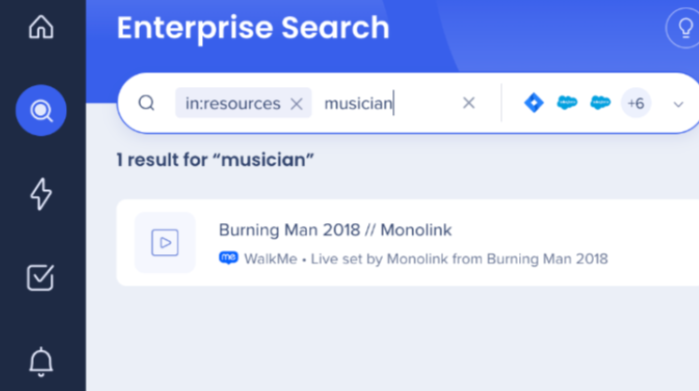
Notez qu'une correspondance exacte n'est pas nécessaire. Par exemple, un élément avec le mot-clé peut toujours apparaître dans les résultats de recherche pour le terme musician
Séparer chaque mot possible en tant que mot-clé peut nuire aux résultats de recherche.
-
Par exemple, le mot-clé correspondra à des termes comme , et ainsi de suite, si chaque mot est pris en compte comme un mot-clé distinct. Il est donc préférable d'être plus précis comme mentionné ci-dessus pour réduire les faux positifs tout en le rendant utile pour les recherches partielles
Indexation
Le menu de bureau/mobile n'indexe pas les résultats. Certaines données sont stockées du côté client. Par exemple, les données qui apparaissent dans les résultats « Résultats de la recherche » récents ou dans le widget « Vu récemment ».
Le reste des données affichées à l'utilisateur sur le flux de recherche est apporté en temps réel à partir de l'API d'applications tierces.
Intégrations
La recherche d'entreprise utilise des intégrations tierces pour mettre en œuvre une « recherche fédérale ». Les recherches dans le menu bureau/mobile sont prises en charge par un moteur NLP et une base de données des graphiques prenant en charge une excellente expérience utilisateur. La recherche d'entreprise n'indexe pas les données tierces dans une base de données consultable de manière indépendante. Consultez le diagramme de séquence ci-dessous qui décrit l'algorithme de recherche :
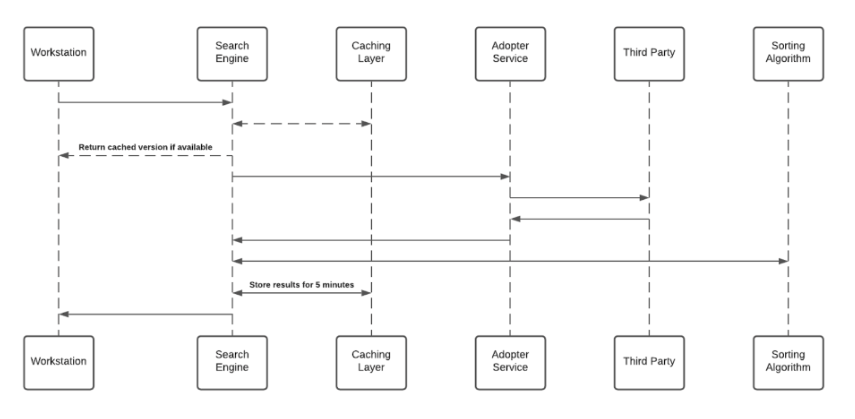
- La couche cache enregistre les résultats pendant une période de cinq minutes
- Chaque service d'adoption crée un identificateur unique pour les résultats qui n'ont pas d'importance sans accéder à la partie tierce et le stocke dans la base de données des graphiques
Accès à une partie tierce et actualisation des jetons
Pour activer la recherche d'entreprise (et les widgets personnalisés d'espace de travail), chaque employé est tenu d'accorder l'autorisation du menu bureau/mobile pour accéder à une partie tierce. Le processus d'octroi utilise le protocole OAuth2.0. Chaque fois qu'un nouveau jeton d'accès est accordé au menu de bureau/mobile, l'application chiffrera les jetons d'accès et d'actualisation et les stockera dans une base de données distante.
Le processus de chiffrement comprend une clé privée unique (« salt ») qui est générée pour chaque individu au premier amorçage et stockée dans le trousseau de machine locale. La clé salt est irremplaçable et ne peut pas être restaurée. Sa perte entraîne l'annulation de l'accès. Cette mesure de sécurité est prise pour éliminer la dépréciation de l'identité lorsque vous accédez à des données très sensibles.
Consultez le diagramme ci-dessous pour examiner le flux de génération et de stockage de Salt.
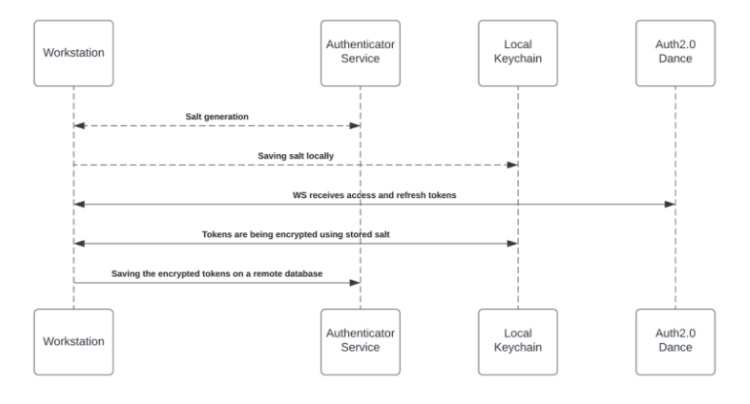
Accéder au contenu d'une partie tierce
L'accès au contenu d'une partie tierce nécessite un consentement de l'utilisateur et, dans certains cas, pour des produits Microsoft principalement, le consentement de l'administration d'une organisation. Les utilisateurs accordent au menu de bureau/mobile l'autorisation nécessaire en approuvant un écran de consentement OAuth2.0 qui est déclenché par eux à partir du menu de bureau/mobile application (« Applications tierces »).
Les applications tierces sont approuvées et vérifiées par des produits tiers. À la fin du processus d'octroi, les applications tierces fournissent un accès et une actualisation des jetons qui sont utilisés par le moteur de recherche pour établir les demandes.
Consultez la section Accès à une partie tierce et Actualisation des jetons pour plus d'informations concernant le mécanisme de stockage.
Lors d'une recherche, le moteur de recherche transfère la demande, avant d'atteindre le service d'adoption, par le biais de l'injecteur de jeton ; un service qui injecte les jetons pertinents pour accomplir la requête. La clé privée locale est transférée à la demande de recherche HTTPS pour un déchiffrage d'exécution.
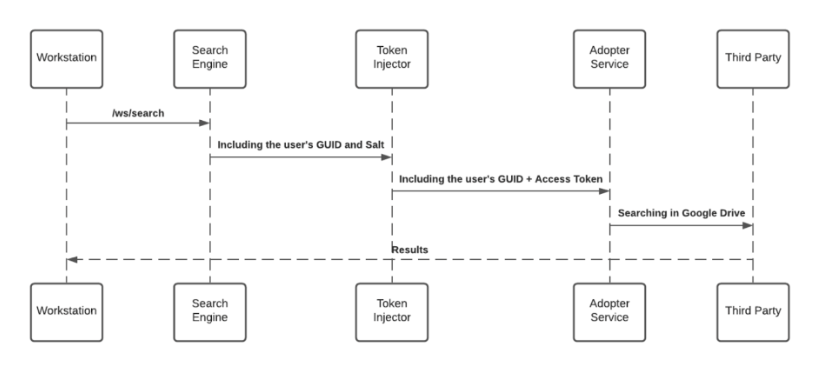
Protection de JWT
Lorsqu'un utilisateur lance une requête de recherche, la recherche d'entreprise WalkMe démarre un flux de recherche qui est protégé par un JWT attribué par l'intégration IDP de WalkMe, dans le cadre du flux de signature de l'utilisateur final :
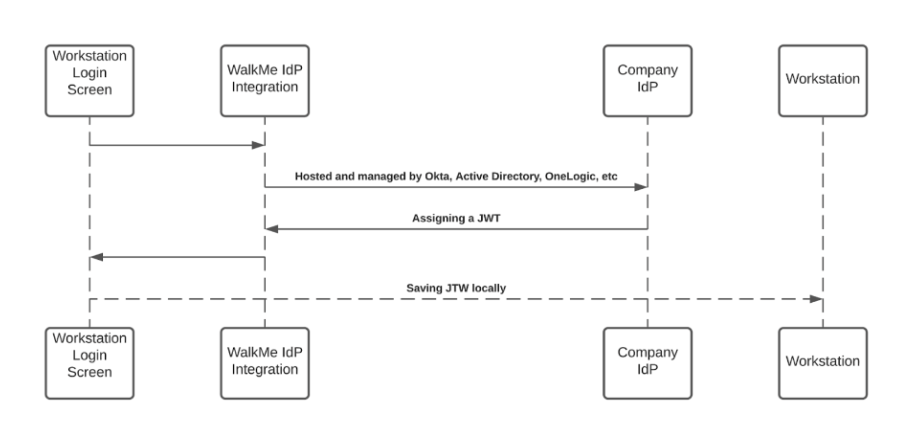
Le JWT envoie l'identité de l'utilisateur et conserve toute requête HTTPS sécurisée et individuelle.
Toutes les demandes de menu de bureau/mobile sont protégées par une validation JWT.
En savoir plus sur la sécurité de l'intégration ici.
Recherche floue
La recherche floue fournit une auto-correction aux requêtes de recherche. La recherche comprend intelligemment l'intention des utilisateurs et fournit des résultats pertinents, même s'il y a des erreurs mineures ou des fautes d'orthographe dans les requêtes de recherche.
Nous prenons en charge deux options pour la correction automatique :
Correction automatique de la bibliothèque
- Configuration requise ? Non, cela fonctionne par défaut pour tous les systèmes
- Limites linguistiques : anglais uniquement
- Nombre de caractères : 3 ou plus
Évitez les correctifs de recherche incorrects
Si les utilisateurs corrigent une expression 3 fois ou plus, cela évitera de la corriger à l'avenir. Cela afin d'éviter les scénarios suivants :



