Brief Overview
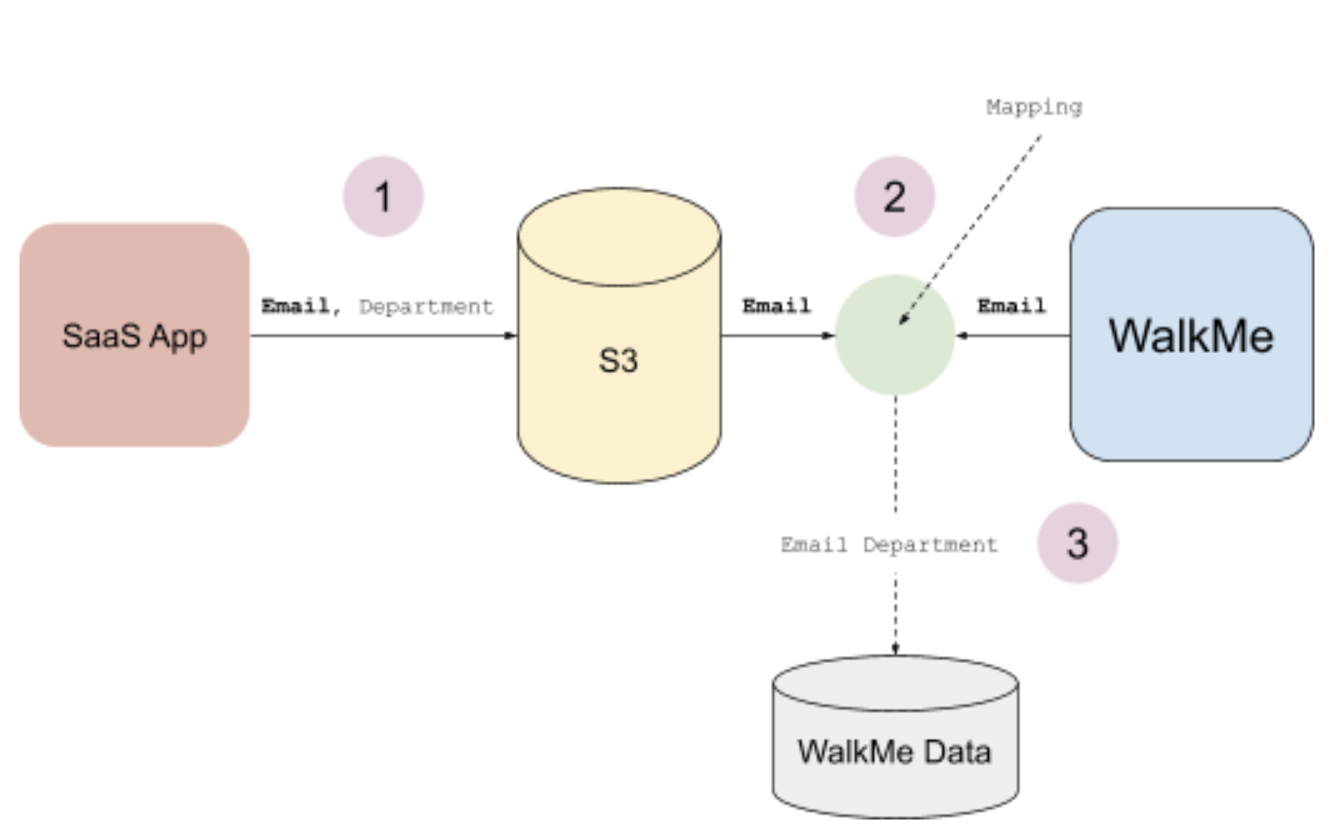
S3 Incoming Integrations can connect any third-party software, on top of S3, to WalkMe. The integration pulls attributes and populates data into WalkMe to use data from external systems in WalkMe for analytics and content segmentation.
Use Cases
Target WalkMe content based on CRM attributes:
- Display a ShoutOut only to "premium users" on your site
- Show a Smart Walk-Thru internally to employees that are from a specific department
- Use as a “User” filter category in Insights and our Report Builder
Target WalkMe content based on Customer Support / Success (such as ServiceNow, Zendesk) attributes:
- Show an NPS survey to all customers that opened more than 2 support tickets
Prerequisites
In order to map the integration attributes into WalkMe, a unique user id needs to be defined and the 3rd party service for integration needs the data to be stored on S3 in a CSV format.
You can then place the CSV file on a specific bucket on S3 and WalkMe will then read this file and based on this file attribution information can target end users.
Creating an Incoming Integration
- Open Insights Classic
- Go to the Integrations page

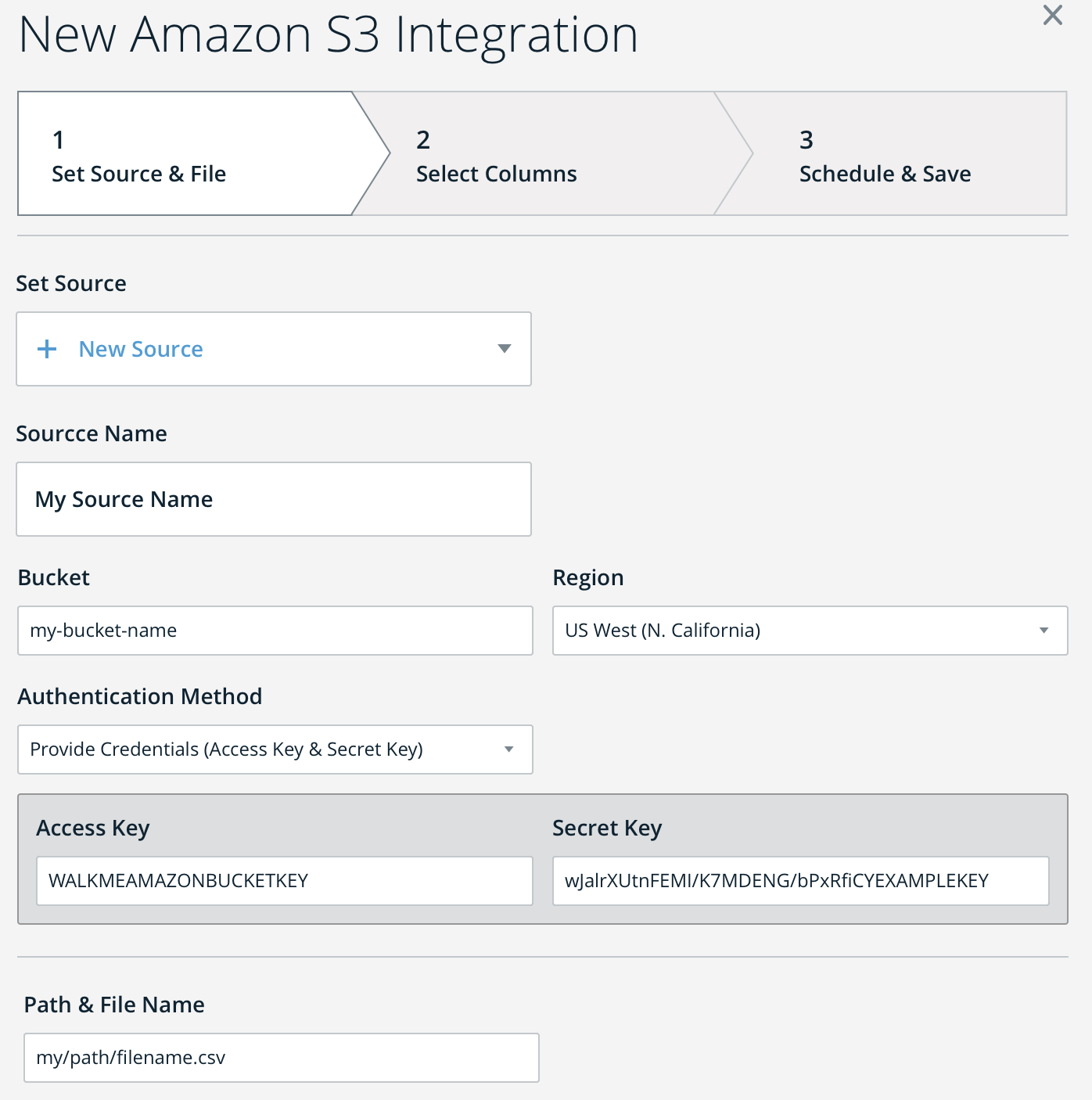
- Click "+ New Integration" and follow the wizard instructions to set up your S3 bucket URL, permissions, and source file (CSV)
- Note: Basic authentication is supported and can be provided during setup (see below)
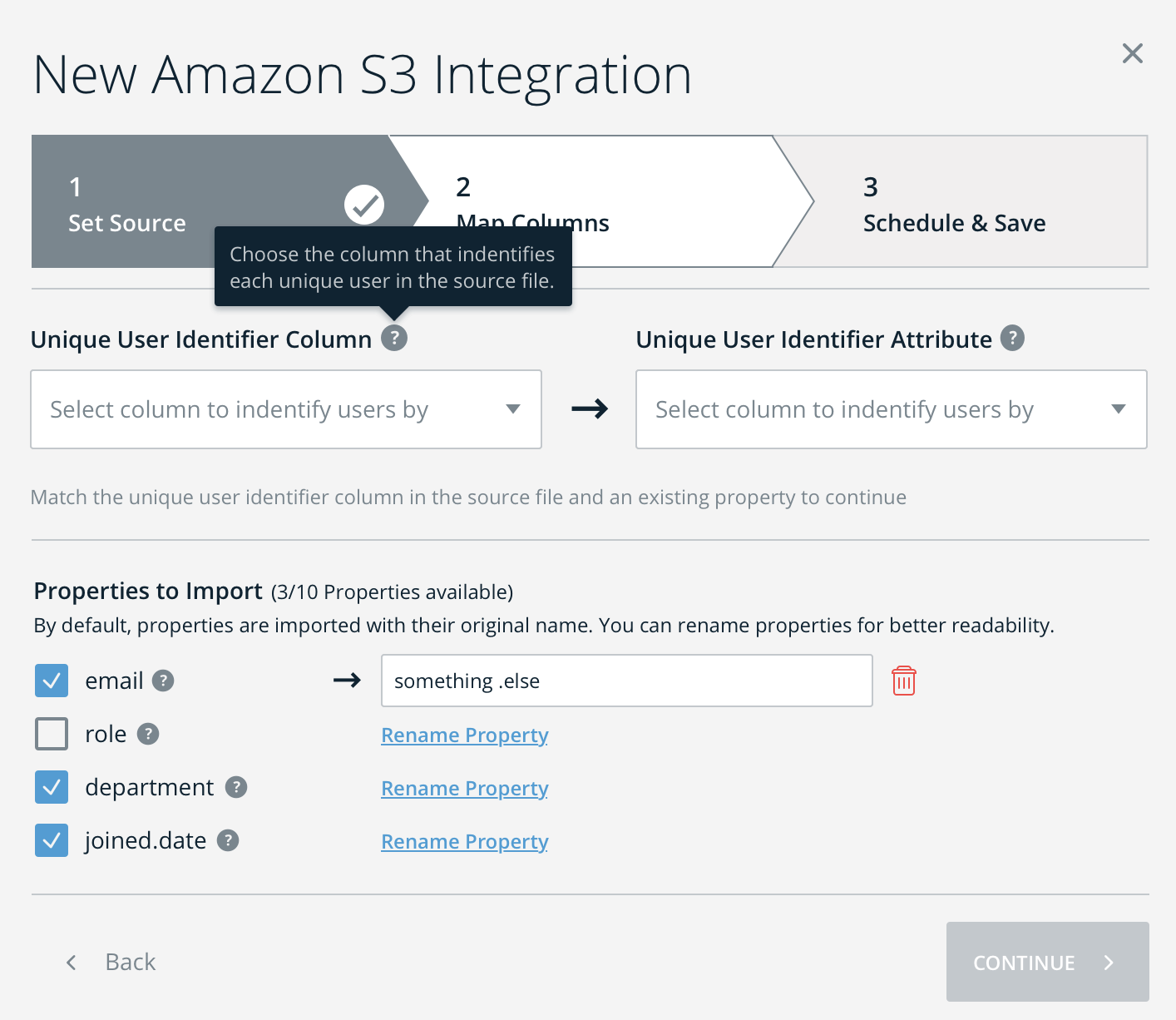
- After data discovery, map the user identifier and select the wanted properties (i.e. attributes) to pass on to WalkMe for targeting
- Note: You can change the names of these properties if desired (this is the name you will see in the Editor)
- A prerequisite for using the integration is setting up a Unique User ID in the WalkMe Editor
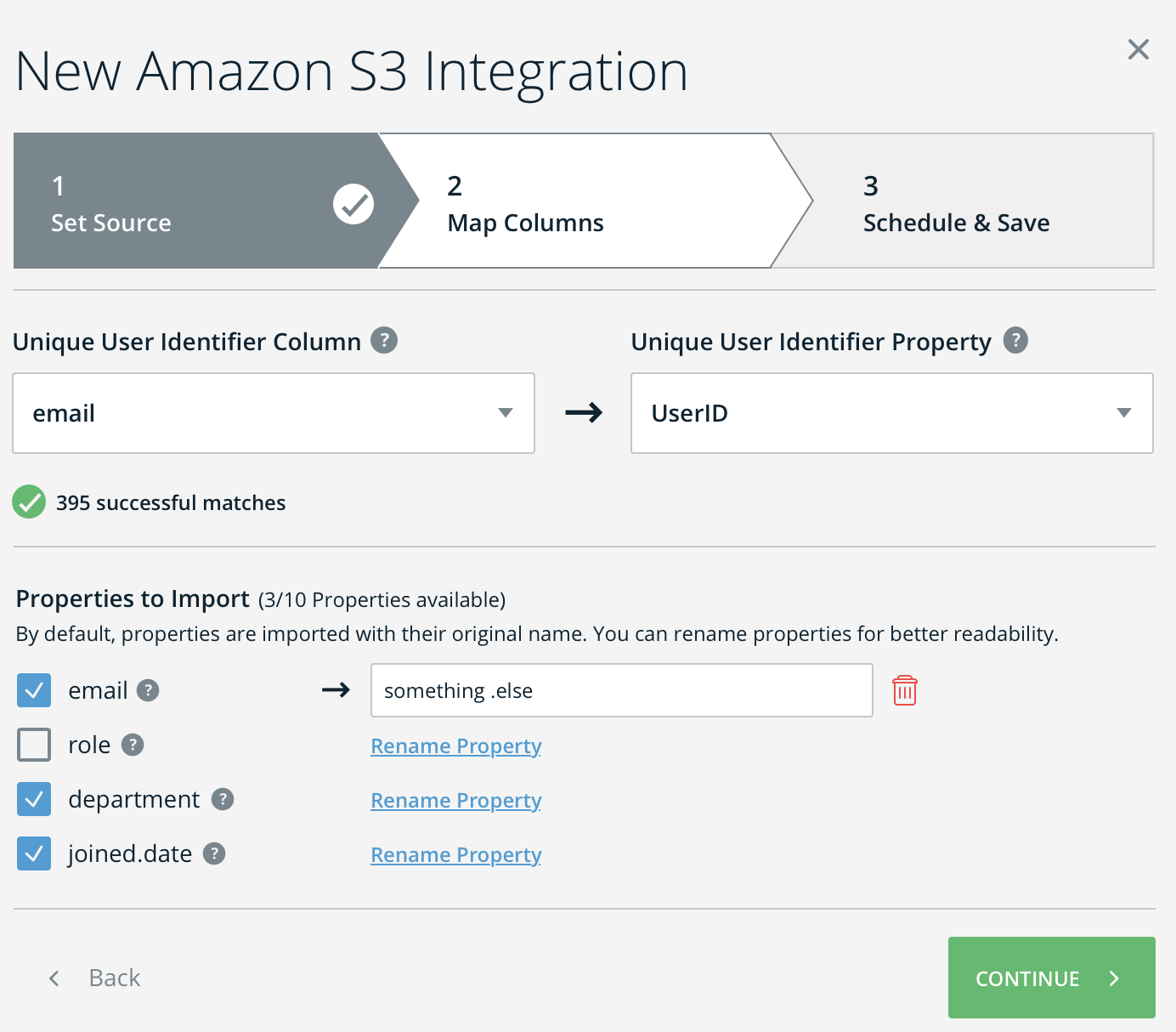
- After completing step 3, you will receive a success or failure message
- If necessary, follow the instructions to resolve the failure
- Click Continue
- Give the new Amazon S3 Integration a name and set the desired import schedule (Incoming integrations work by pulling the CSV file from the S3 bucket according to a set synchronization interval)
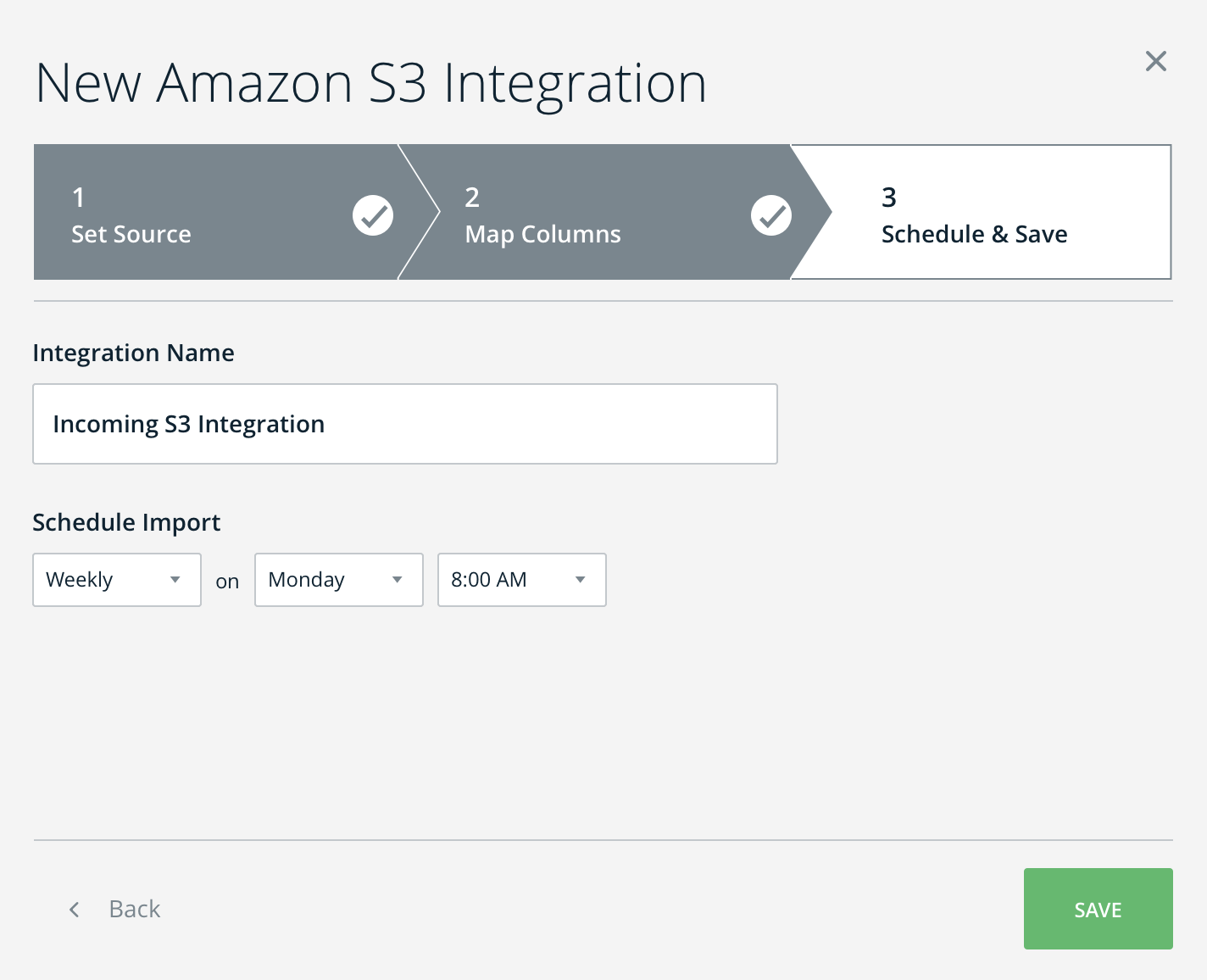
- See the newly created integration in the integrations management table
The report will be sent in CSV format.
Integrations Management Table
From this table, you can modify and delete integrations and see the following properties:
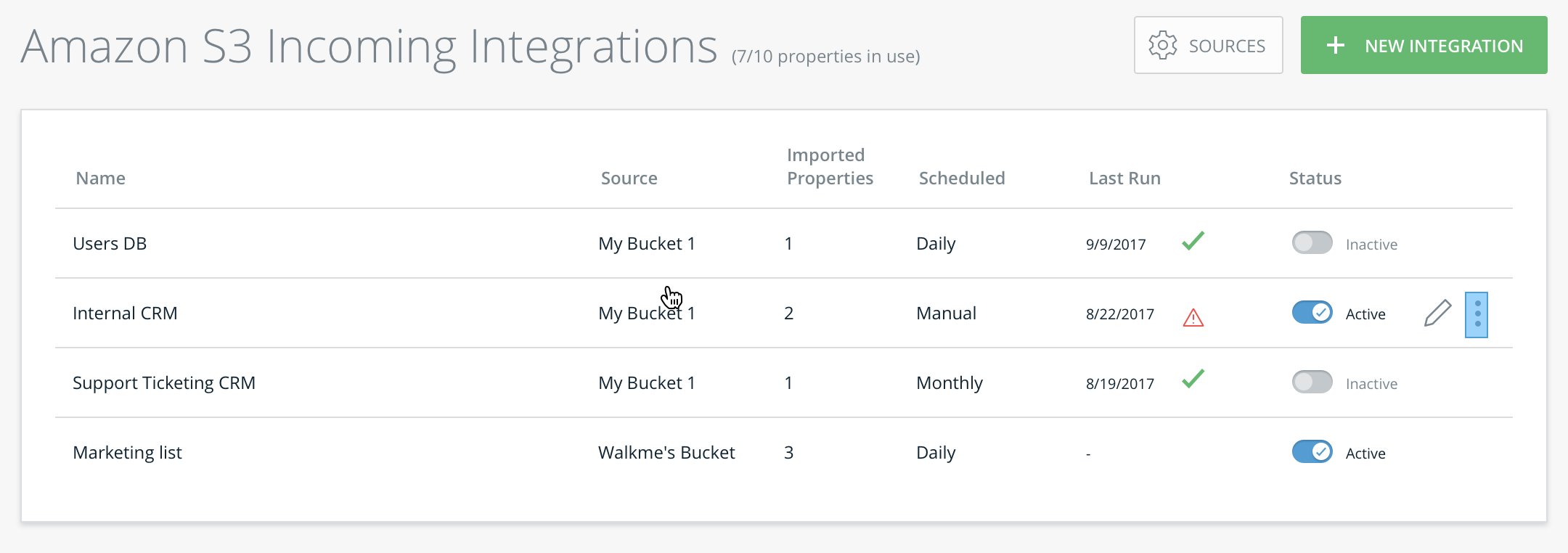
- Name of integration
- Integration source
- Number of successfully imported properties
- Import schedule
- Date of the last run
- Whether the last run was successful or not (shown with a green check mark or red danger icon)
- Status toggle
- Use this to activate or deactivate an Integration:
Best Practices
- When completing the integration creation process, before targeting content in the editor make sure that you have at least one successful integration run in the Incoming integration's table
- When modifying an integration, changes will be populated in the next scheduled run
- You may need to modify/pause your segment before that
- Less is more - Be sensitive with the total number of attributes that you integrate to WalkMe
- We allow a total of 100 attributes total across all of the integrations
Segmenting Content According to Integration Data
After creating an S3 Integration successfully, you can use the incoming data within the WalkMe Editor to create targeted rules and segmentation for your WalkMe content:

Note
Be sure to type your attribute exactly as it was defined when creating the integration during the setup process.
Shared File Integrations
If you plan to use a shared file for multiple integrations, it's important to note that you will need to create a separate integration for each file.
Insights has a specific way of processing data for each integration, and it looks for a particular file location. Once the data has been processed, the file is then moved to a designated folder for either "success" or "failed" files within the defined location.
If a second integration tries to access the same file, it won't be able to locate it since the file has already been moved. This will cause the second integration to fail.
To avoid this issue, set up a separate integration for each file, even if they are using the same data source. This will ensure that each integration can access the file it needs without conflicting with other integrations.
Technical Notes
- Extra buckets cannot be created
- Instead, new sub-folders can only be created within the existing bucket, due to security reasons
- No limit to the number of rows for the integrated file; however, file size is limited to 1GB


